When news are true, but CLONED
There is fake news, that is the more or less “alternative-” facts published specifically for political propaganda, or just to make some buck. But there is also news that are true but deliberately CLONED, like animals in factory farms. Here is a real-world example from Italy (IMPORTANT UPDATE, July 17th 2018, at the bottom of the post!!)
<u><em><strong>CAPTION:</strong>
<a href="/img/00-gruppoamiche.it-germania.xyz.png" target="_blank">click for larger version</a>
</em></u>
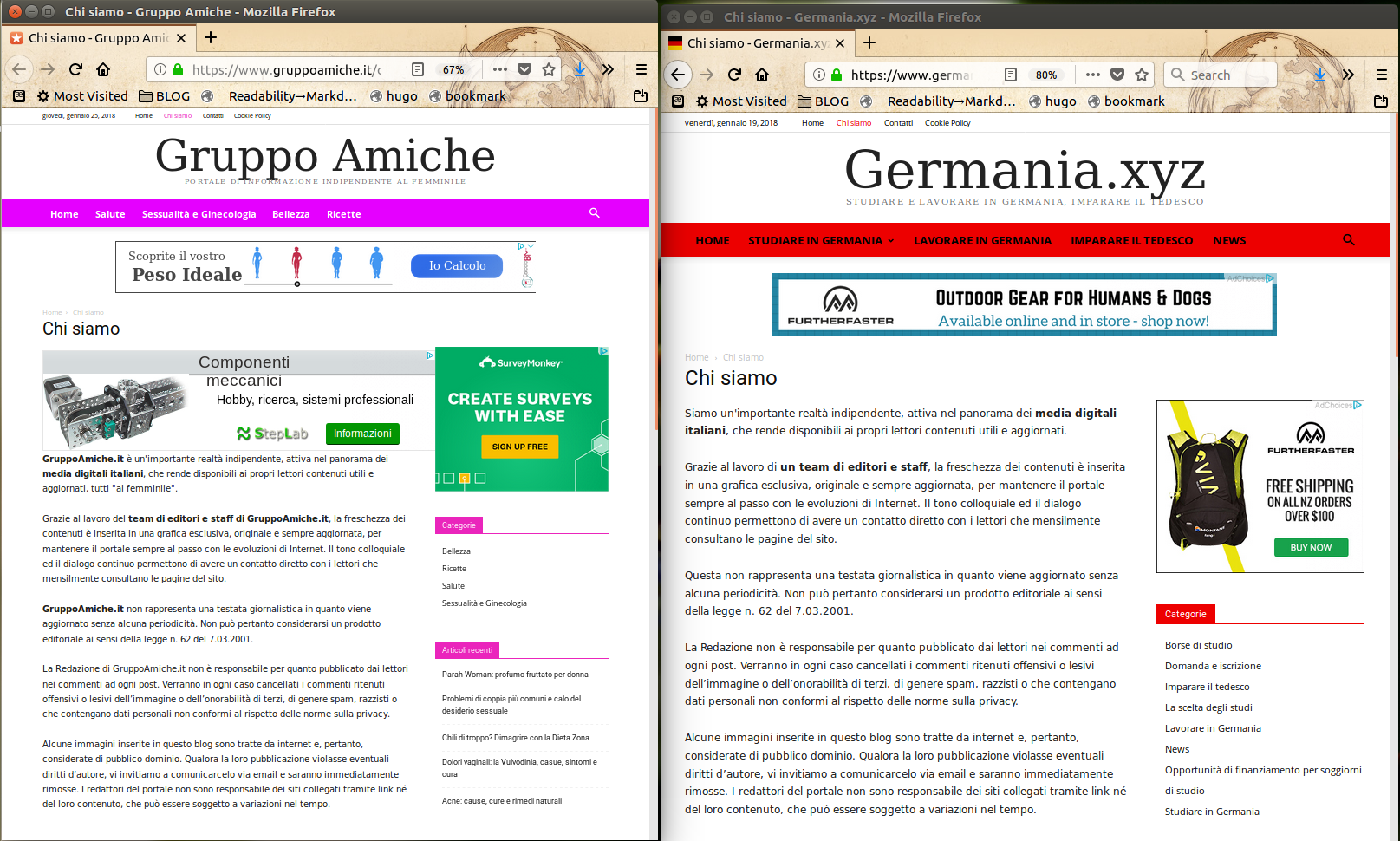
Even if you do not understand Italian, a quick look at the “Chi Siamo” (=“Who we are”) pages of these seven websites:
- www.germania.xyz
- www.gruppoamiche.it
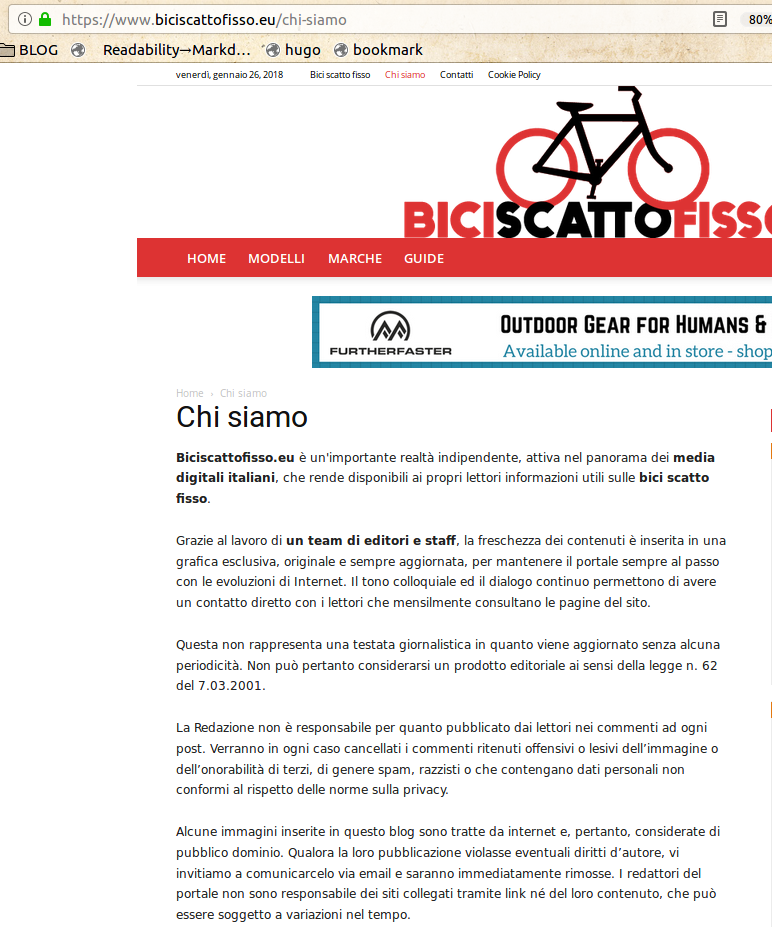
- www.biciscattofisso.eu
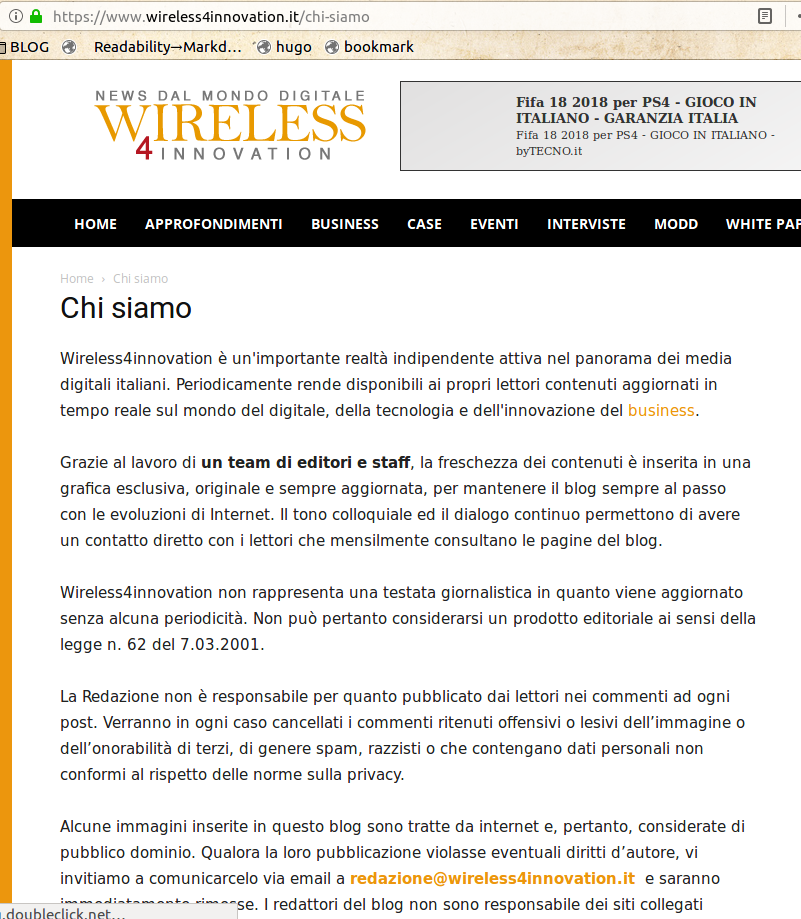
- www.wireless4innovation.it
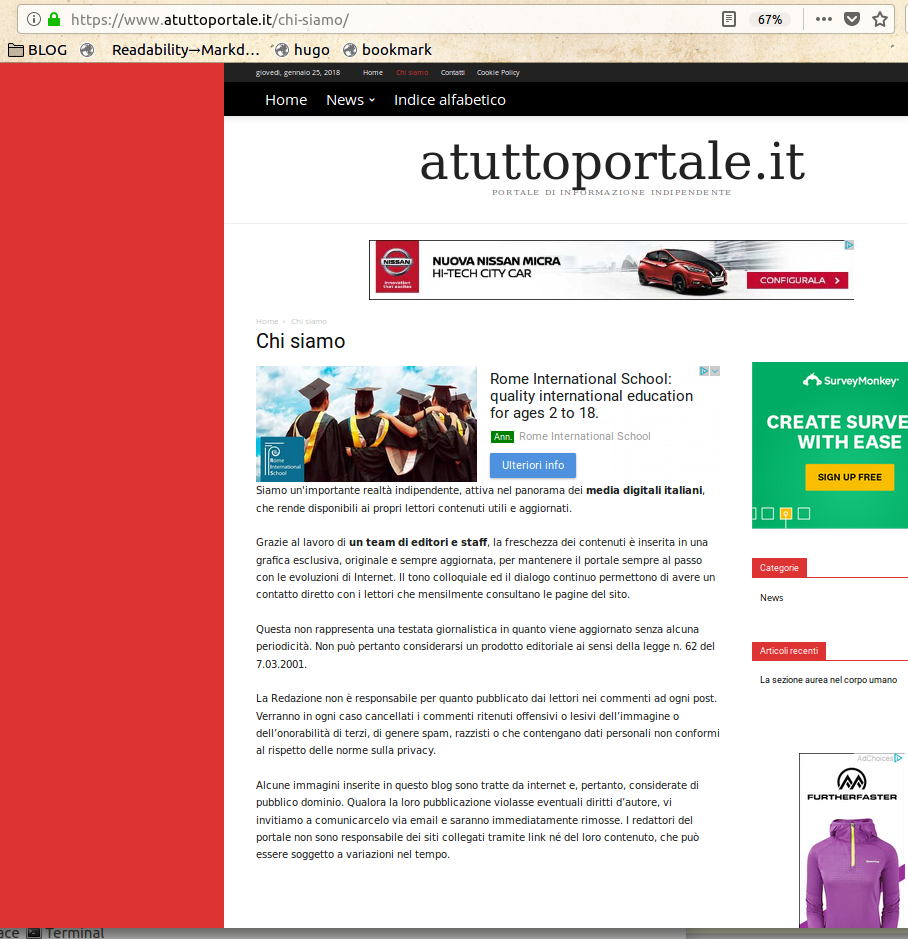
- www.atuttoportale.it
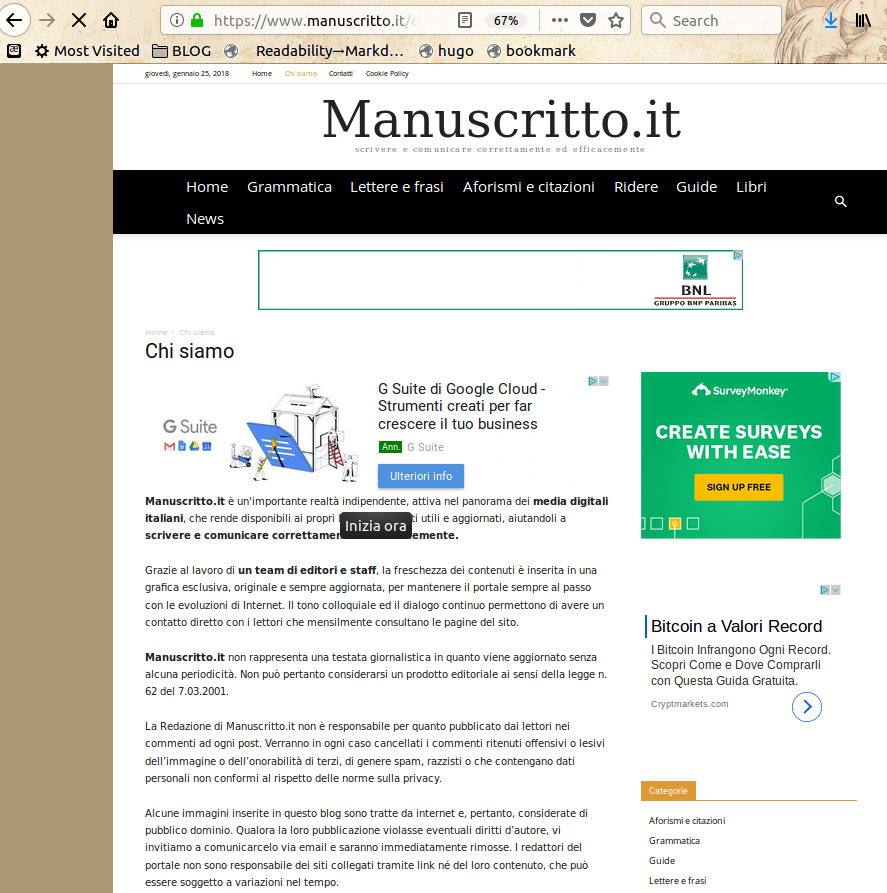
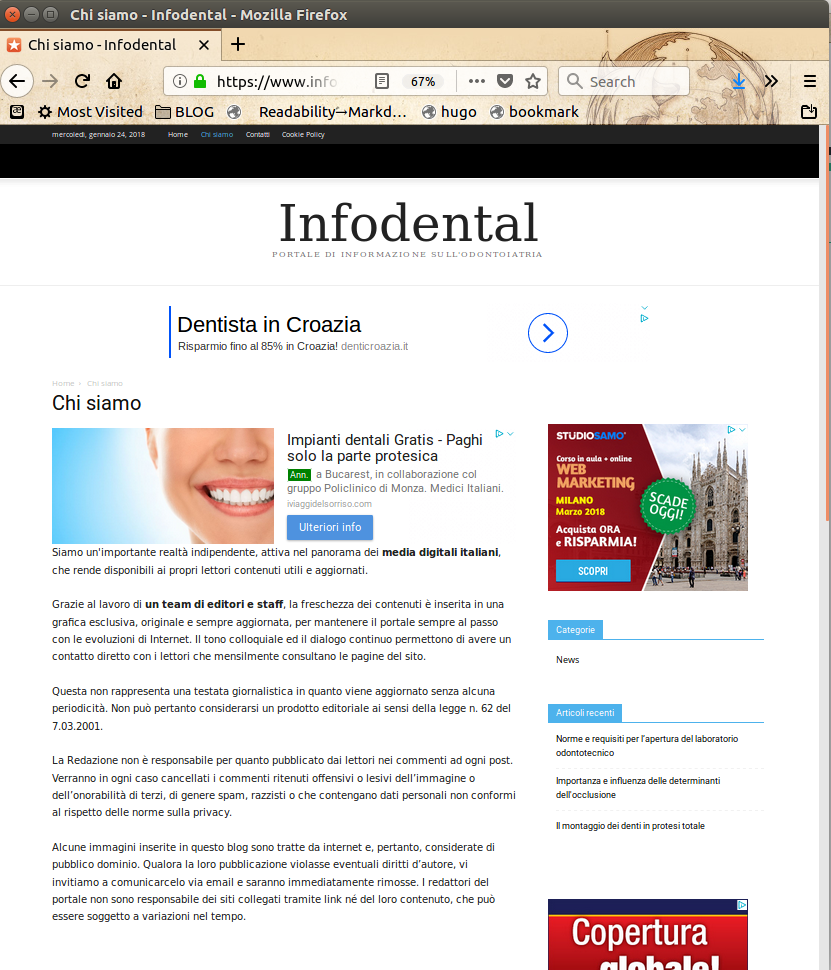
- www.manuscritto.it
- www.infodental.it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(click on their names to see the last five) is enough to realize that their texts are identical, and that the whole websites are all “clones”, made with the very same template. Among other things, all those “Chi Siamo” pages say that those websites are published by:
"an important independent reality, active in the italian digital media landscape, that makes up to date and useful content available for its readers."“Thanks to a team of editors, the freshness of our content is embedded in an exclusive, original and always up to date look… Some images in this blog are taken from the Internet, and are therefore considered public domain."
exclusive and original those looks are NOT, are they now? Apart from looks, the content of those pages immediately prompts questions like:
- why should one really independent reality use as its own introductory text content copied verbatim by people working in totally different sectors?
- if the “independent” reality behind all those websites covering wildly unrelated websites is always one and the same, there would be nothing bad, so why aren’t they clearly spelling out their name?
- how can any “important reality” in online publishing still repeat that HUGE LIE that stuff found online is, by default, be considered in the public domain? That’s the biggest Internet lie!
“Freshness of THEIR content”? Really?
All those pages say that, “thanks to the work of a team of editors, their content are up to date and “fresh””. Let’s see.
The page titled “Lavorare in Germania: FAQ e informazioni generali” (“Working in Germany: FAQ and general info”) of the first website of the list is a mere copy of the one titled “Lavori per studenti e informazioni generali” (“Student jobs and general info” of “Servizio Tedesco per lo Scambio Accademico” (German Service for Academic Exchange, in German: “DAAD - Deutscher Akademischer Austauschdienst”, whose website is www.daad.it (but vising www.daad-italia.it redirects you to… guess where?):
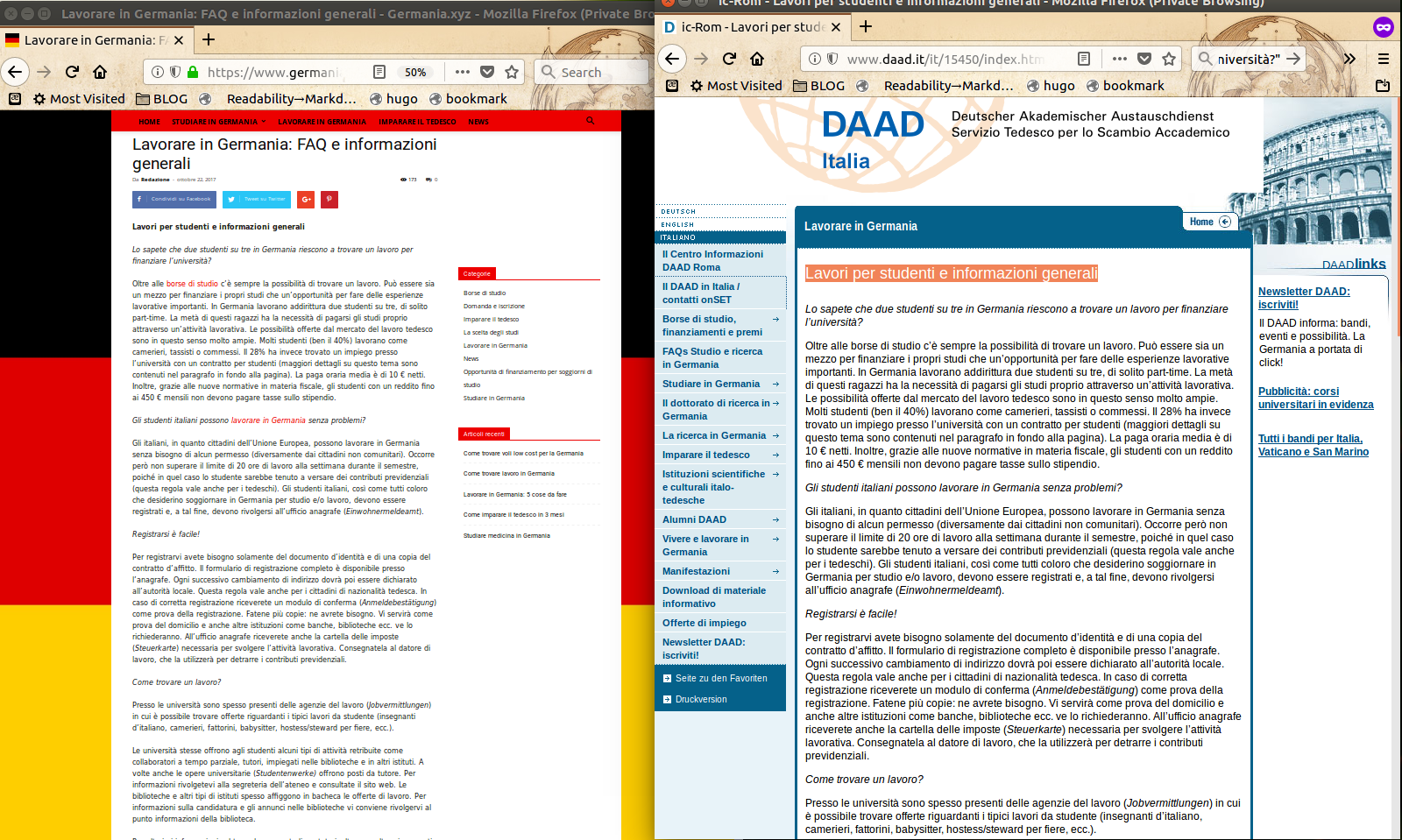
<u><em><strong>CAPTION:</strong>
<a href="/img/05-lavorare-in-germania-germania.xyz.vs.daad.png" target="_blank">click for larger version</a>
</em></u>
Website number 4 has a page copied from this “All Rights Reserved” one of Pagamentidigitali.it:
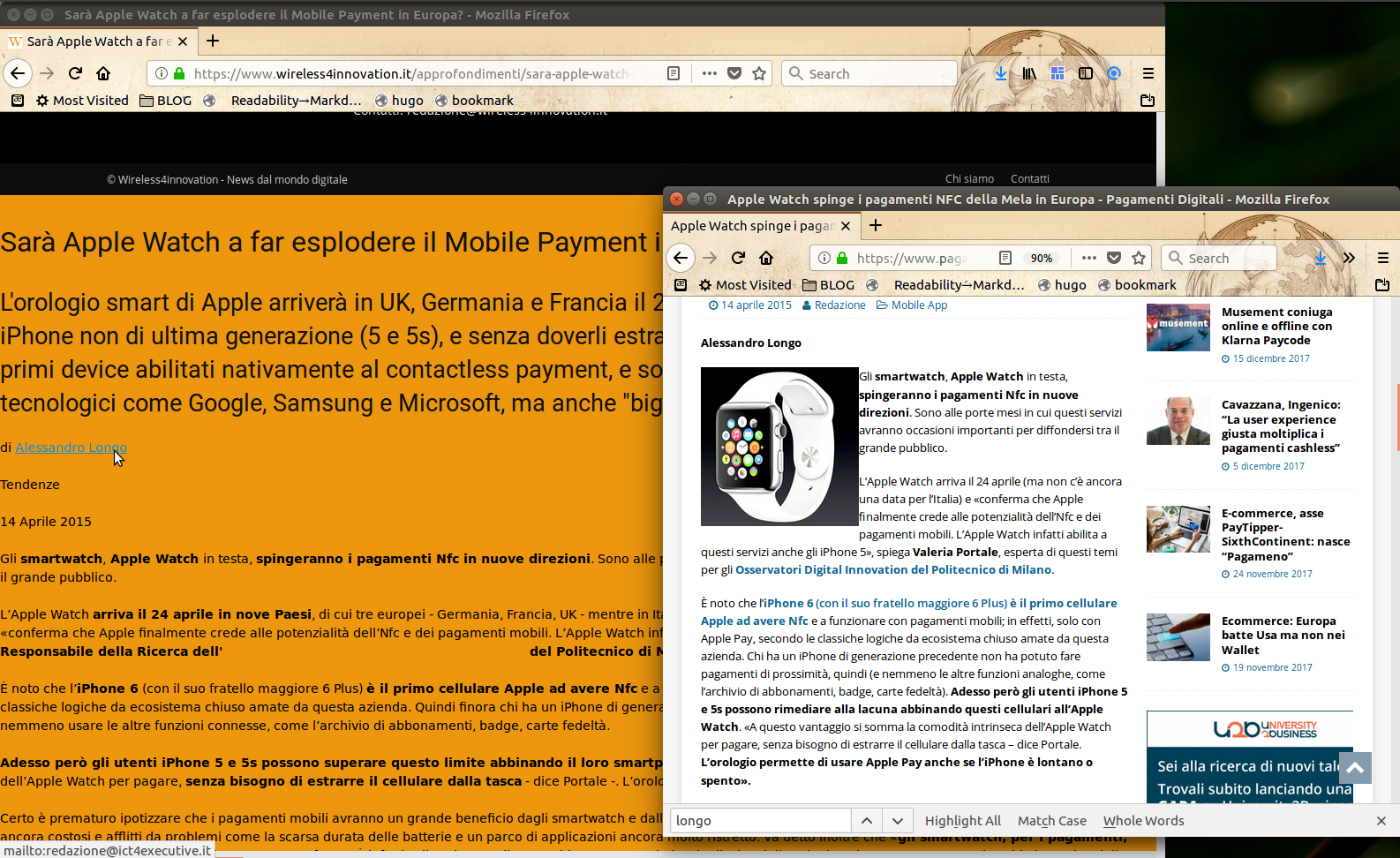
<u><em><strong>CAPTION:</strong>
<a href="/img/06-wireless4innovation-vs-pagamentidigitali.it.png" target="_blank">click for larger version</a>
</em></u>
The Golden Section post of website n. 5 seems copied from here and/or here:
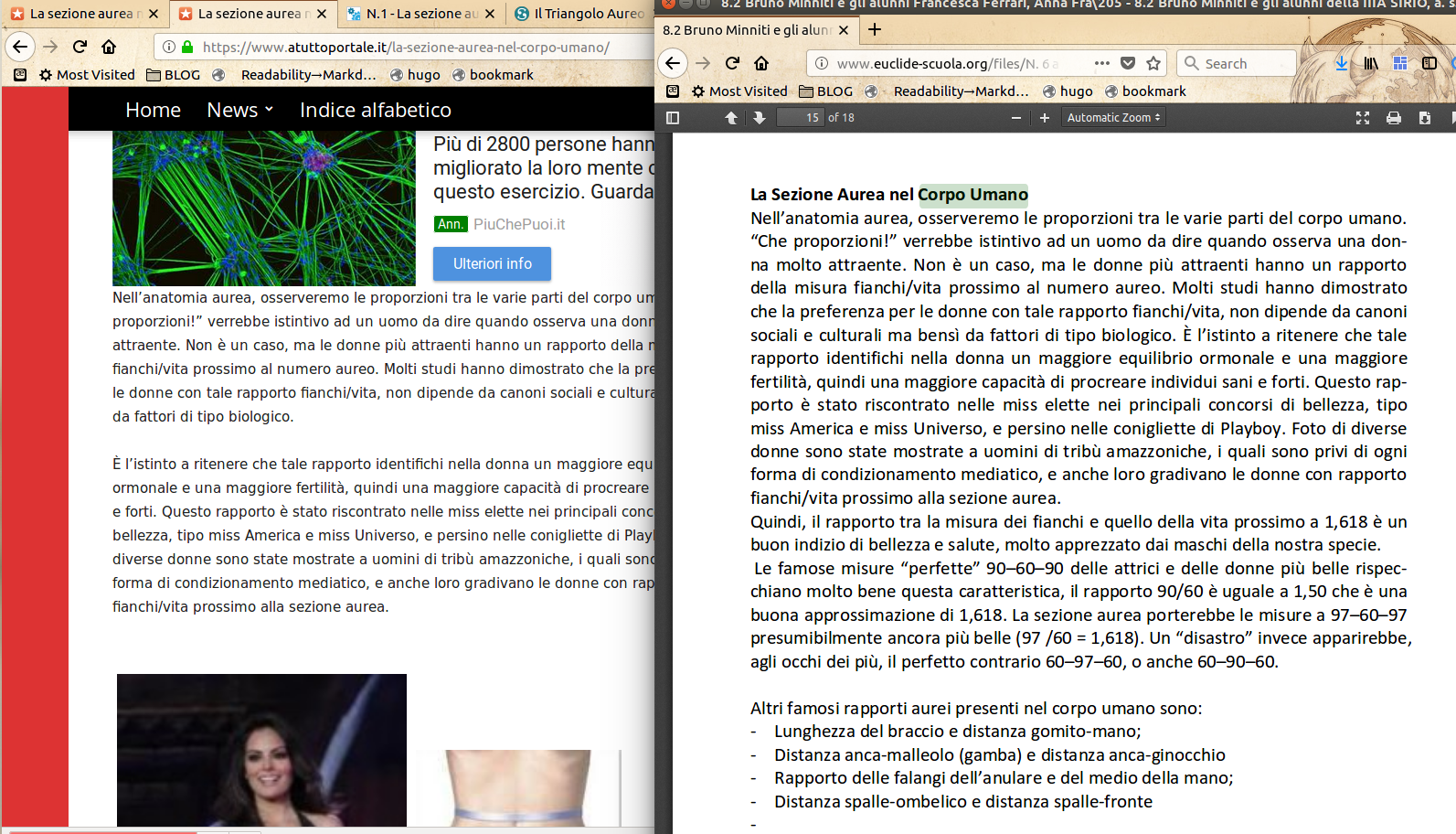
<u><em><strong>CAPTION:</strong>
<a href="/img/07-atuttoportalesezioneaurea.png" target="_blank">click for larger version</a>
</em></u>
The “thoughts on women (“riflessioni sulle donne”) of website n. 6 seem a mere “copy and paste” from winnyweb and other pages:
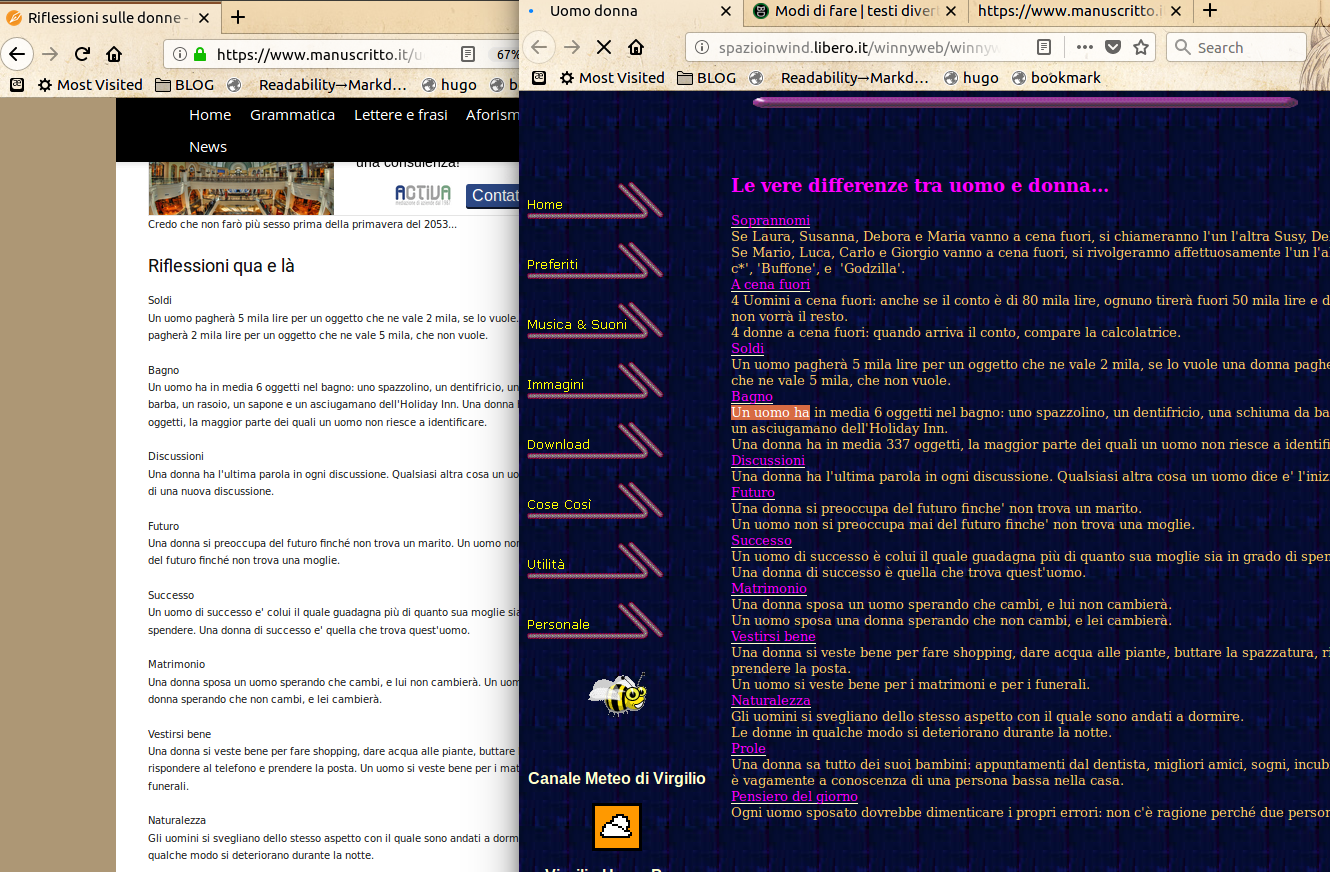
<u><em><strong>CAPTION:</strong>
<a href="/img/08-manuscritto.it-vs-winnyweb.png" target="_blank">click for larger version</a>
</em></u>
“Norme e requisiti per l’apertura del laboratorio odontotecnico” (“Rules and requirements for opening a dental technician lab”) of website n. 7 are a partial copy of this page (and please note that none of those pages is official, or linking to official sources, that is giving visitors the guarantee that they are looking at complete, up to date information on how to start such a complex business):
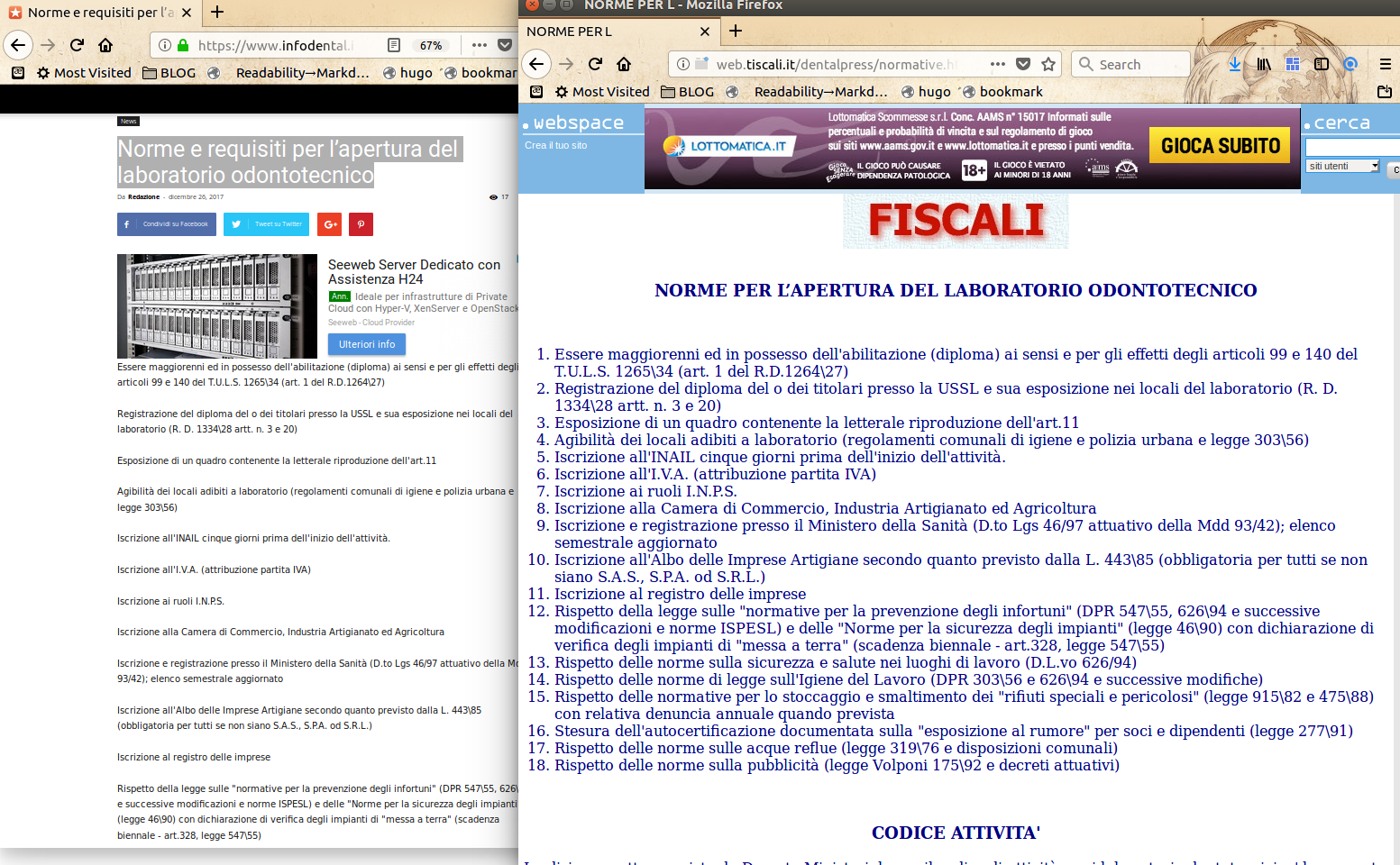
<u><em><strong>CAPTION:</strong>
<a href="/img/09-infodental.it-vs-dentalpress.png" target="_blank">click for larger version</a>
</em></u>
Last but not least… the post published in January 2018 on website n. 2 about “Problemi di coppia più comuni e calo del desiderio sessuale” (“Most common couple problems, and lack of sexual desire”) which is presented as declarations straight from “Prof. Marco Rossi, psychiatrist and sexologist who participate(d) to the MTV show Loveline” contains a photograph copied (I believe) from a brazilian article published in May 2017 (which is explicitly labeled as “Todos os direitos reservados “, not “Pubblic Domain”), and the first part of the text is almost identical to something published by psychologist in Naples not prof. Rossi:
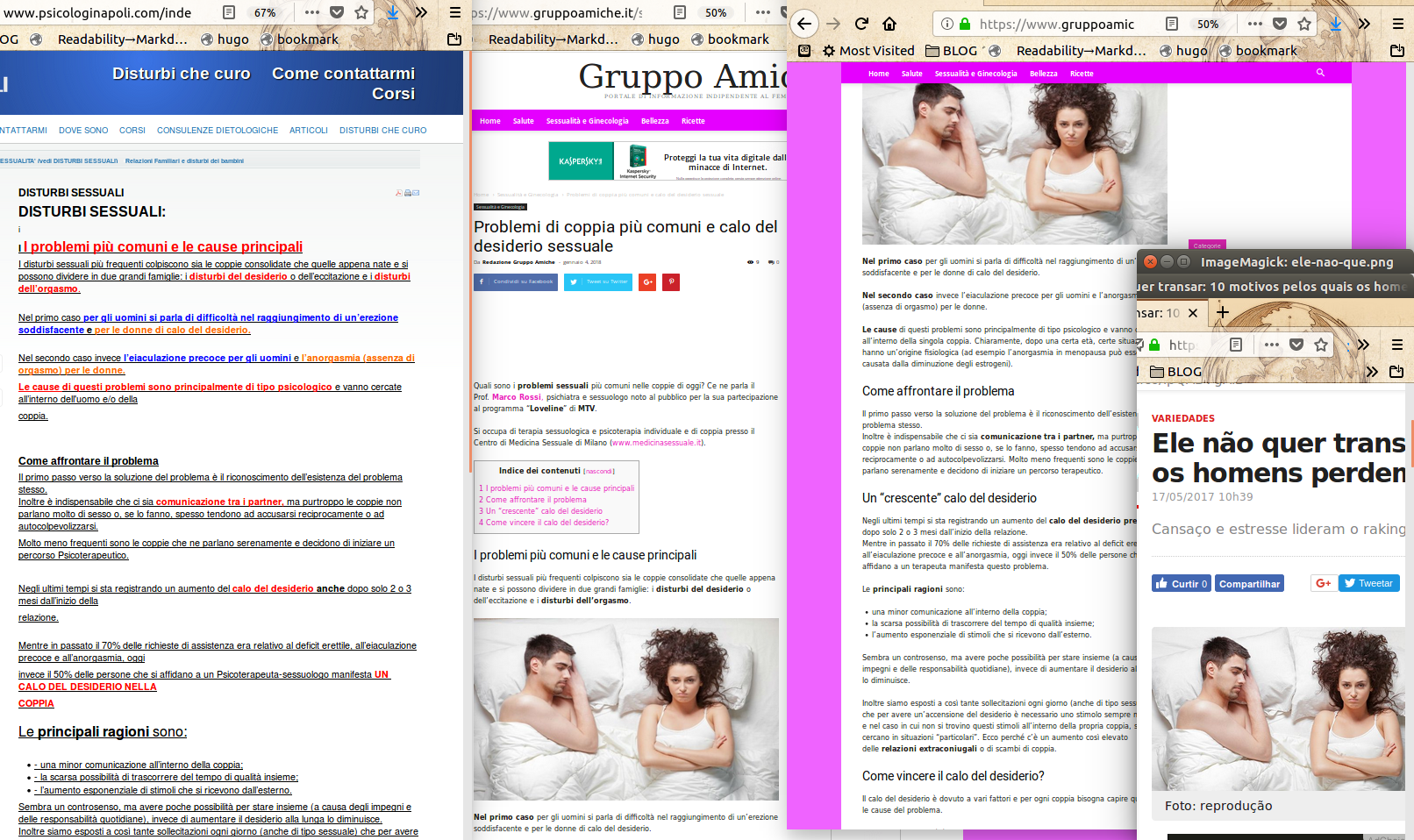
<u><em><strong>CAPTION:</strong>
<a href="/img/problemi-di-coppia.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Why?
Looking at the source code of those pages confirms the sensation that there is only one group behind them all, and shows why:
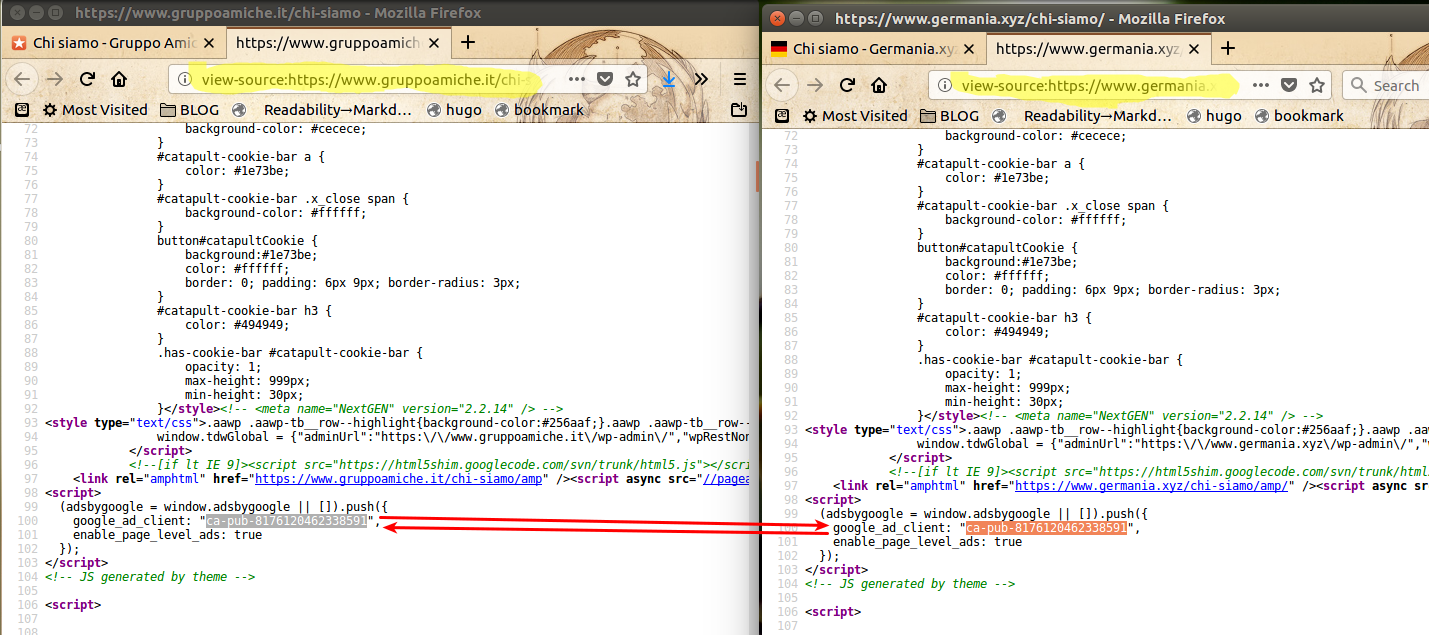
<u><em><strong>CAPTION:</strong>
<a href="/img/10-adsense-code-gruppoamiche.it-germania.xyz.highlighted.png" target="_blank">click for larger version</a>
</em></u>
You can check yourself the source code of those seven websites, to see that they all share the same Google Adsense code (ca-pub-8176120462338591). This means that all the profits from all the banners that Google inserts on all those websites end up in the same pockets.
What should we do of websites with cloned news?
Of course, there is nothing wrong with making (or helping others to make) money with online advertising, or with marketing in general. Even doing it in “Content Farm” fashion isn’t always and automatically evil.
Ditto for combining, reformatting properly, in a world REALLY rewrite already existing content, through one’s actual effort (as long as licenses are respected, of course!). As a matter of fact, this last practice often turns into a public utility service, by making clearer and more usable staff that already existed, but was poorly written.
Instead, and regardless of money, publishing also stuff that is flat out copied, without even proper attribution on every single copy.. that really doesn’t look professional, to say the least. No “important, independent reality” should ever lower itself to using such cheap tricks. Even if it happens once every 20 posts, and without any copyright violations. No?
In practice, even if you’re sure that some website violated copyright, or otherwise violated the license of some content, don’t waste time and energy with lawyers. Use the same quick, cheap and reliable method that I routinely use in similar cases.
Even if you choose that route, however, the real problem remains WHO you should contact to save time and effort. Especially in cases like these when the individuals who actually did the copyng (maybe without even informing the publisher…) may be temporary, independent contractors who don’t know each other, or even the existence of the other websites of the network. It’s much better to go search directly THE common owner of all the websites (exactly because, as shown above, very likely is always the same entity).
Finding who that entity is is quite simple. Just go on websites like Domaintools or Whois.net, enter the domain name and note (unless they obscured it…) who is listed as technical or administrative contact, then try to find their online contacts.
Just as example, the contact for the “Germany” domain are hidden, but as of January 26th, 2018, those of GruppoAmiche were listed as:
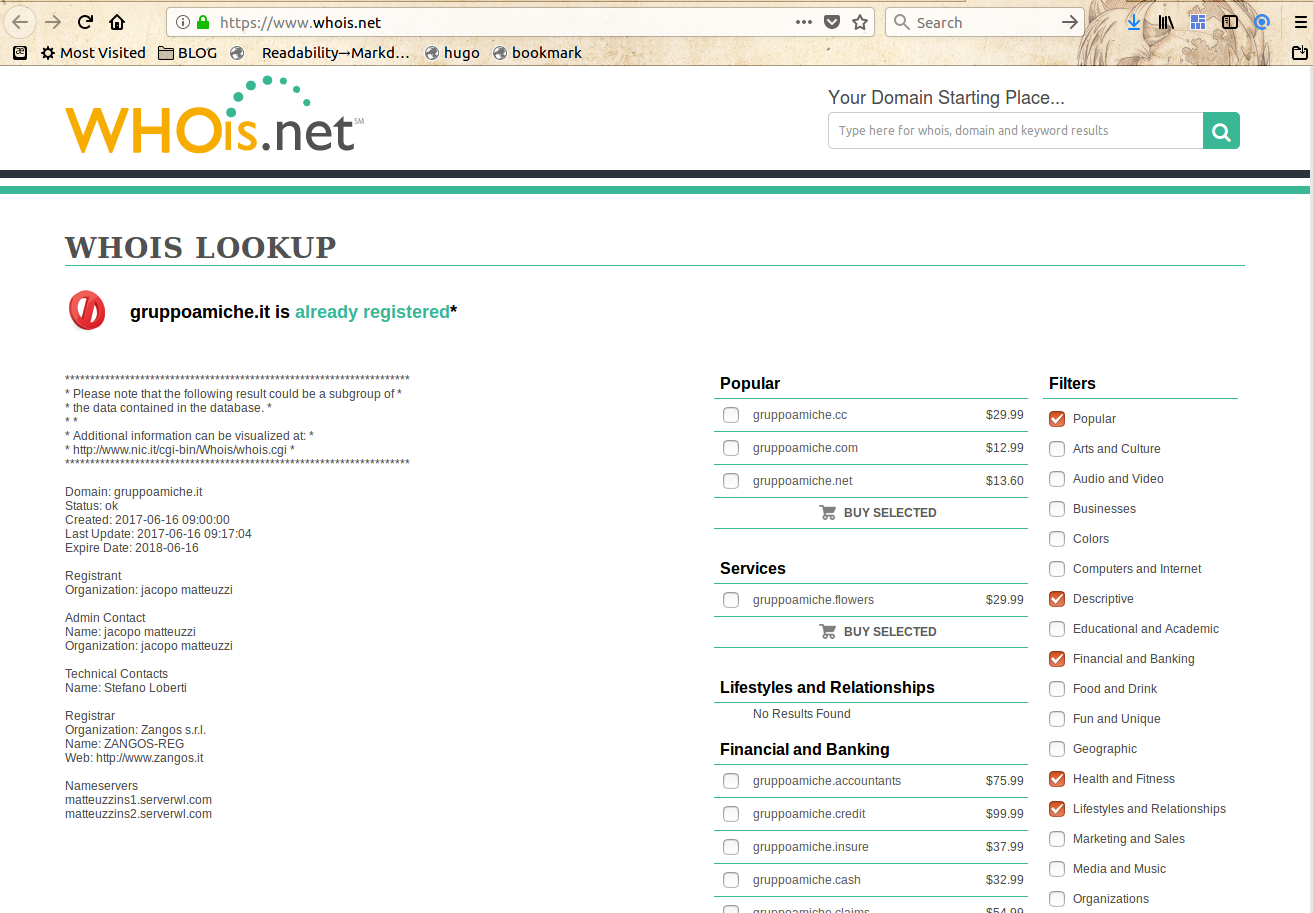
<u><em><strong>CAPTION:</strong>
<a href="/img/01-registrant-gruppoamiche.it.png" target="_blank">click for larger version</a>
</em></u>
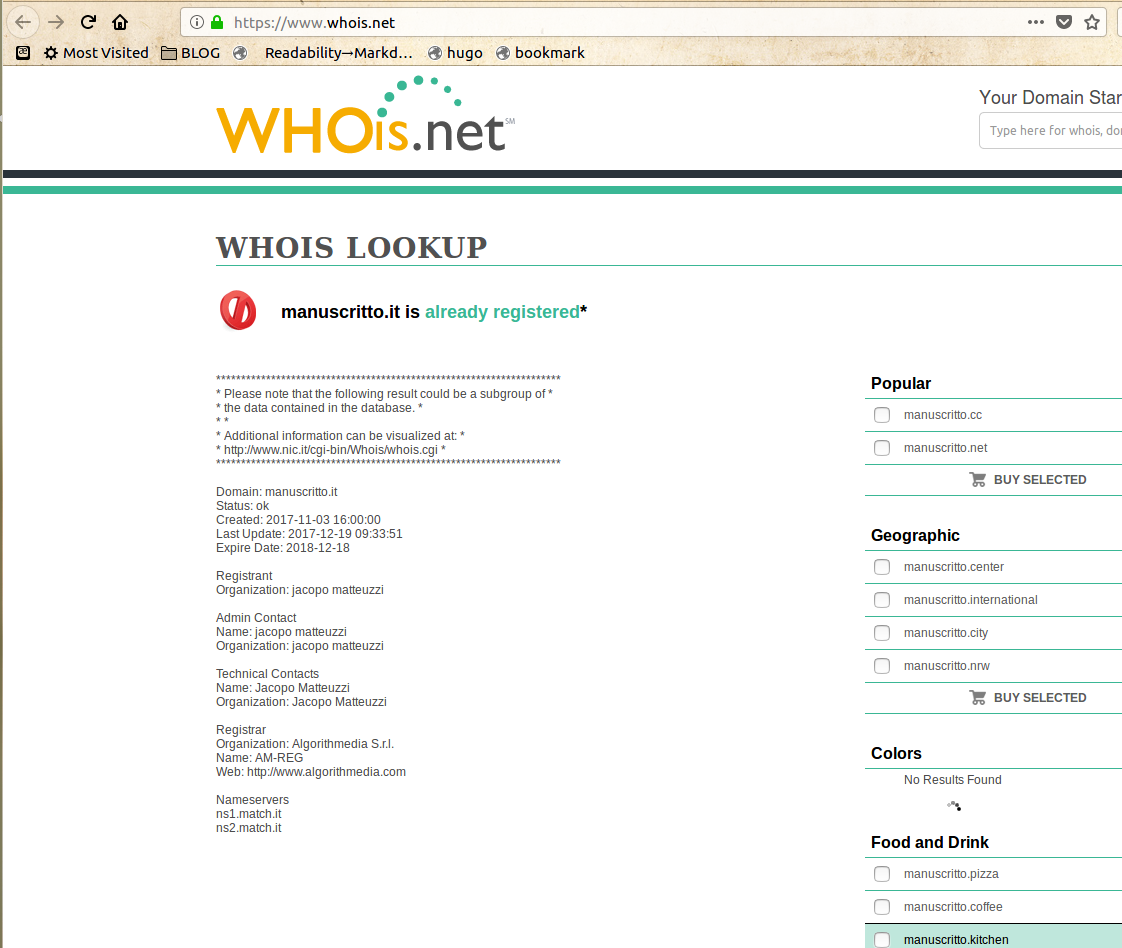
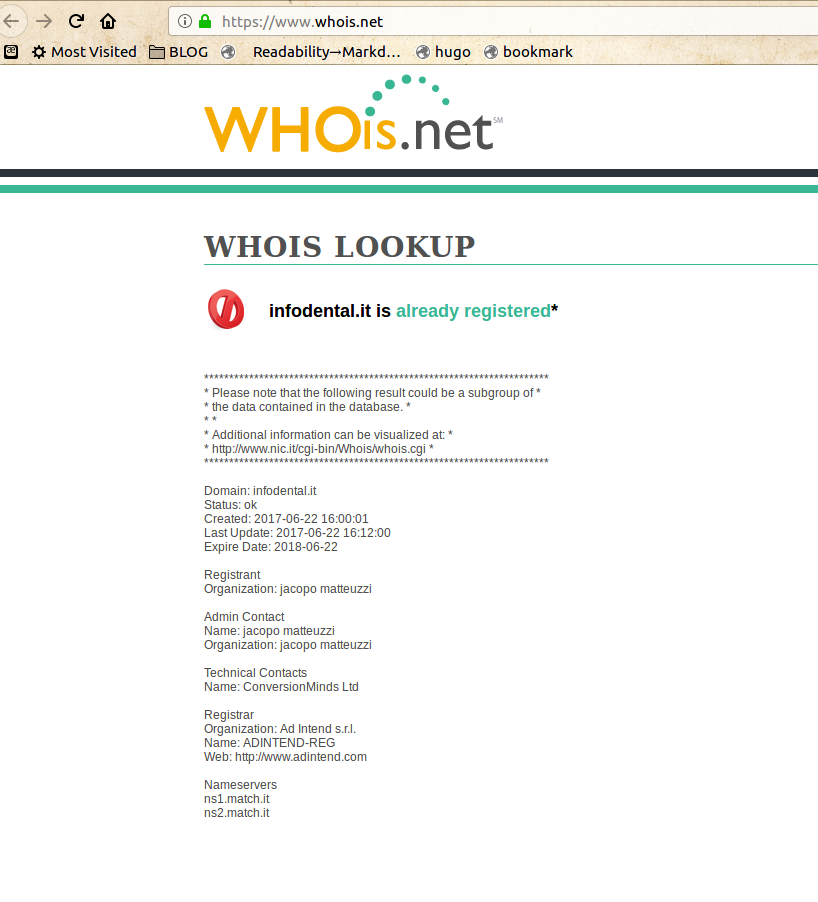
Jacopo Matteuzzi (also for websites n.6 and n.7) and Stefano Loberti. The first Google results for those names are the Co-CEO of a Web Marketing agency and an entrepreneur specialized in online advertising. It’s quite unlikely that it’s really them, for the reasons I already explained. But of course I am ready to publish denials or clarifications by them, or whoever else is actually responsible of those domains!
{kind=link}
{kind=link}
IMPORTANT UPDATE, JULY 17TH, 2018:
Today Mr. Stefano Loberti rightly pointed out to me that he only is, as you can check by yourself inserting those domain names in WHOIS) the technical (meaning: not responsible in any way for the content!) contact for those websites.
Because “the standard rules for the italian registry of domain names mandate that, unless the domain owner explicitly asks otherwise, the technical contact is a representative of the handling the registration (that is, in this case, my (Loberti’s) company Zangos SrL”).
I apologize for not making this fundamental distinction evident in the first version of this post.
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!