Indeed, it seems that Google IS forgetting the old Web
XML pioneer and early blogger Tim Bray says that Google maybe suffers of deliberate memory loss. I may have found more evidence that this is the case.
Bray writes that: “I think Google has stopped indexing the older parts of the Web. I think I can prove it. Google’s competition is doing better.”
Bray’s case: a 2006 review
Back in 2006, Bray published on his own blog a review of a Lou Reed album. A few days ago, when he needed to quote again the URL of that review, he realized that he himself couldn’t find it via Google “Even if you read them first and can carefully conjure up exact-match strings, and then use the “site:” prefix”.
My own case, again from 2006
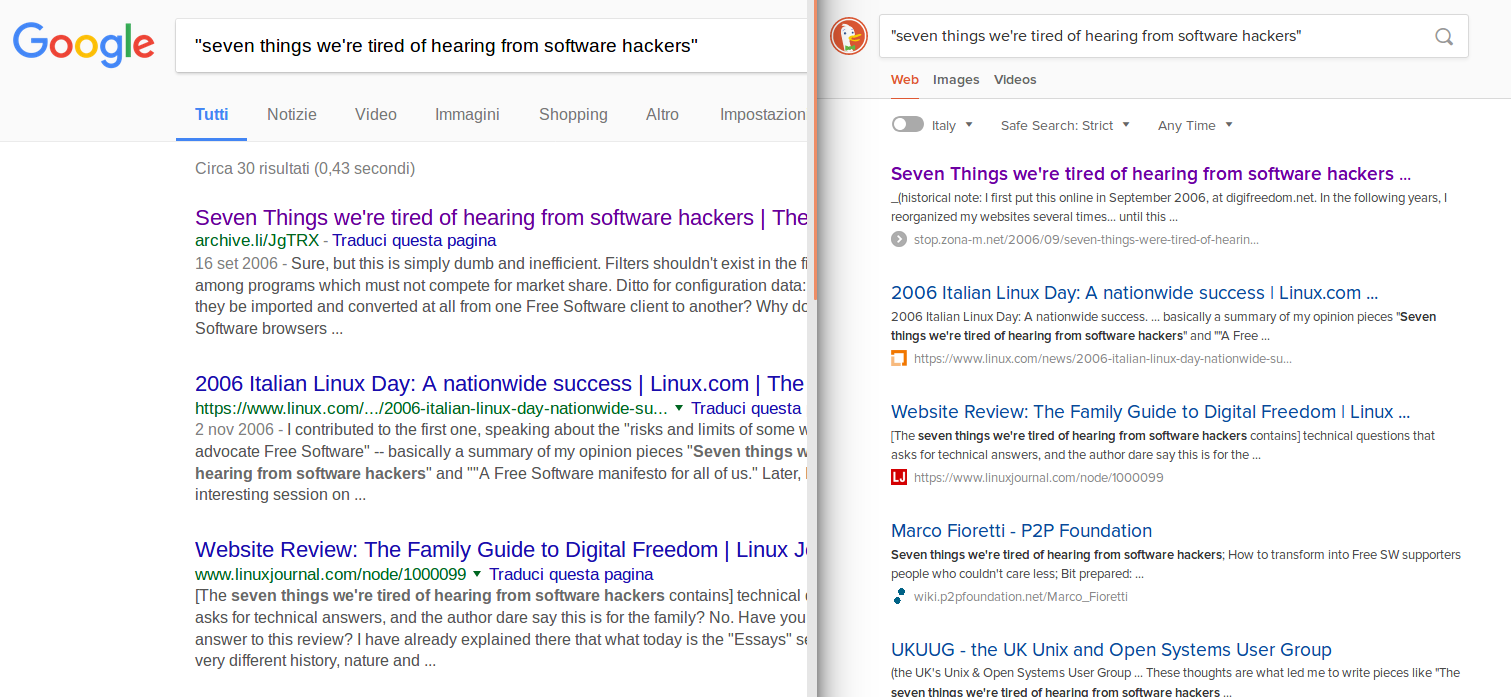
Back in 2006, I published on one of my domains, digifreedom.net, the opinion piece “Seven Things we’re tired of hearing from software hackers”. A few years later, for reasons not relevant here, I froze that whole project. One unwanted consequence was that the “Seven Things”, together with other posts, were not accessible anymore. I was able to put the post back online only in December 2013, at a new URL on this other website. Last Saturday I needed to email that link to a friend and I had exactly the same experience as Bray: Google would only return links to mentions, or even to whole copies, but archived elsewhere. I asked Google to reindex this whole website, but nothing changed. Yesterday afternoon, through BoingBoing I discovered Bray’s post. As soon as I read it, I tried DuckDuckGo and got the same result: Google ignores my copy of my own post, DuckDuckGo correctly lists it as first result (click here for high-resolution screenshot):
{kind=link}
Different stories, same practical result?
Unlike Bray’s, my own post disappeared from the Web for a while, and then reappeared with the original date, but only after a few years, and in a different domain. This is an important difference which may mean that, in my case, part of Google’s failure is my own fault. Still, for all practical purposes, the result is the same:
DuckDuckGo gives as first result the most, if not the only correct answer to whoever would be interested in that post today: the current link to the original version, on the (current) website of its author. DuckDuckGo gets things right. Google does not (not at the time of writing, of course).
Bray concludes that Google deliberately forgets old pages, because “indexing the whole Web is crushingly expensive, and getting more so every day” and Google “cares about giving you great answers to the questions that matter to you right now”. His conclusion is that, if the Web should be “a permanent, long-lived store of humanity’s intellectual heritage… it needs to be indexed, just like a library. Google apparently doesn’t share that view.”
I agree with that conclusion. For the same reason, I also find misleading the title of BoingBoing’s report of this story: “Google’s forgetting the early web”. The two posts mentioned here are not “early web”, nor really “old”. Unless we’re all missing something here, it seems more correct to say that Google forgets stuff that is more than 10 years old. If this is the case, Google will remember and index a smaller part of the web every year. Google may do so simply because it would be impossible to do more, for economical and/or technological constraints, which sooner or later would also hit its competitors. But this only makes bigger the problem of what to remember, what to forget and above all who and how should remember and forget.
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!