Quando le notizie sono vere, ma CLONATE
Ci sono le fake news, cioè le notizie più o meno INVENTATE, specificamente per scopi politici o semplicemente per far soldi. Ma ci sono anche le notizie VERE MA CLONATE, tipo polli in batteria. Per esempio… (IMPORTANTE AGGIORNAMENTO, 17 luglio 2018, vedi fine post!)
<u><em><strong>CAPTION:</strong>
<a href="/img/00-gruppoamiche.it-germania.xyz.png" target="_blank">cliccare per versione più grande</a>
</em></u>
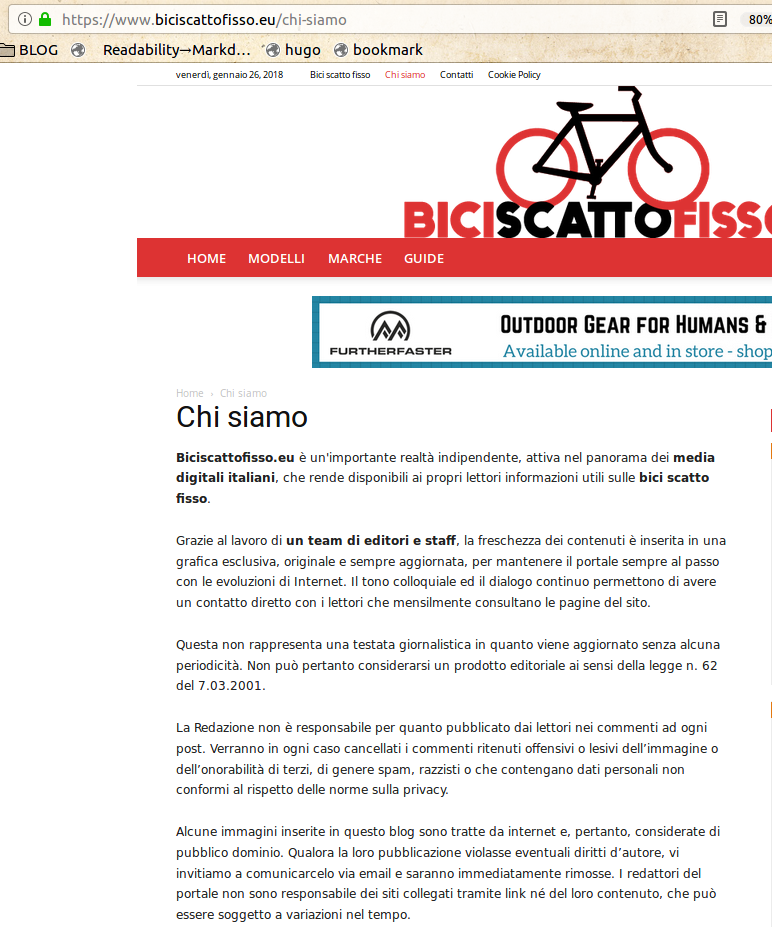
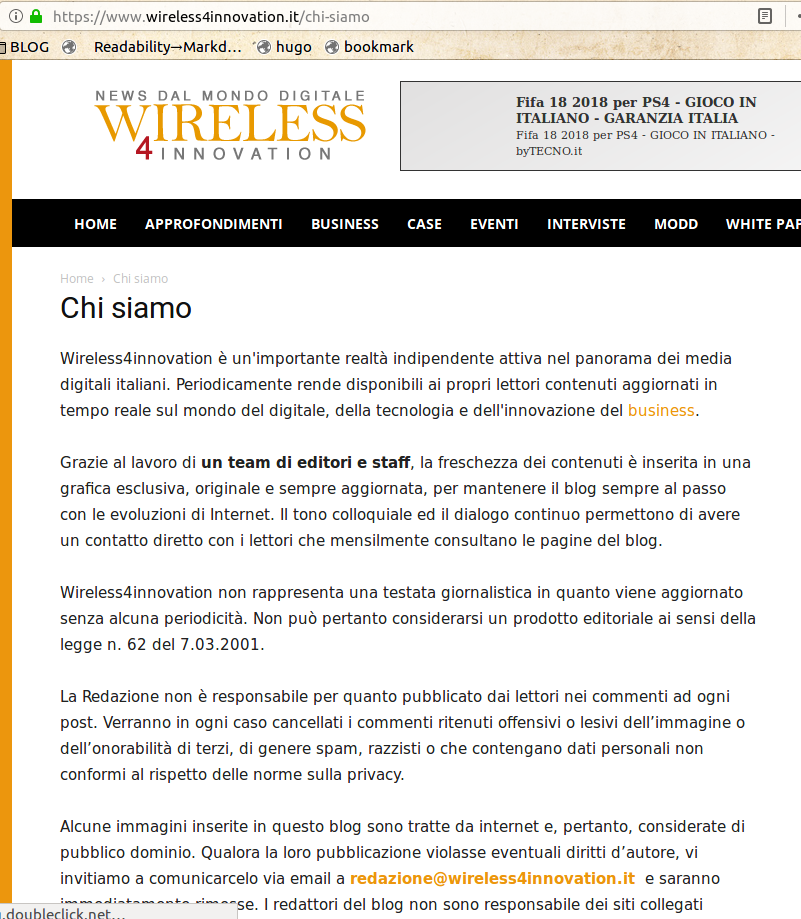
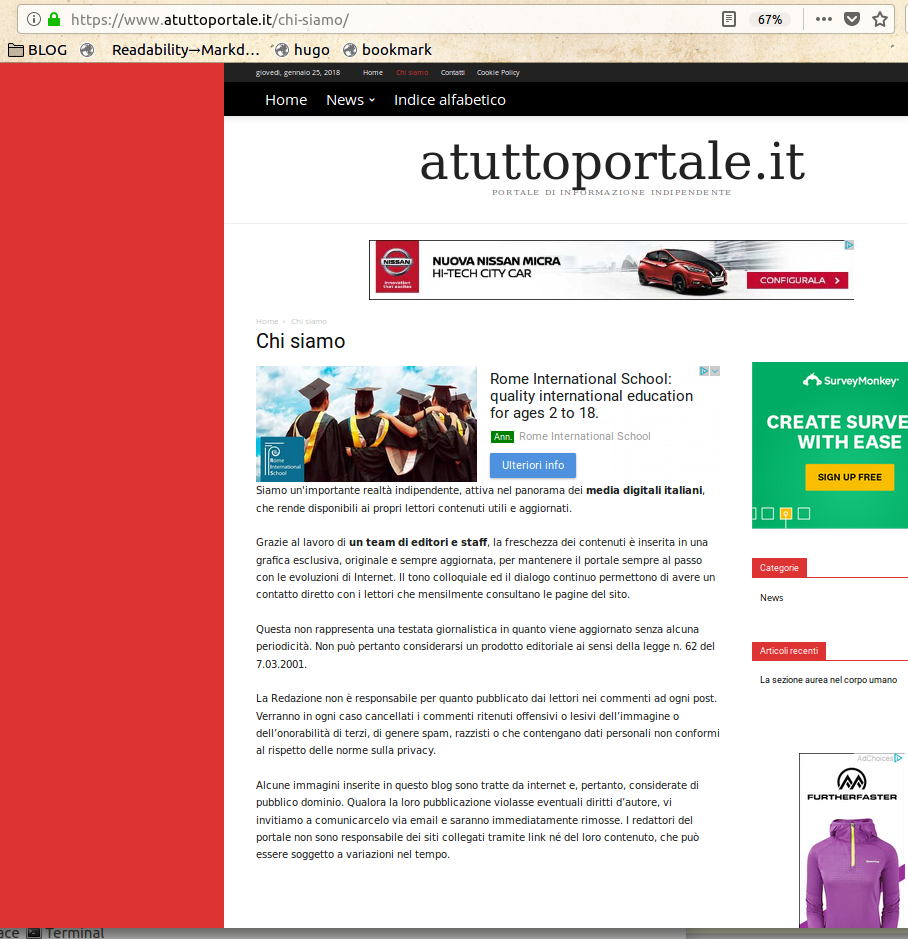
consideriamo questi siti:
- www.germania.xyz
- www.gruppoamiche.it
- www.biciscattofisso.eu
- www.wireless4innovation.it
- www.atuttoportale.it
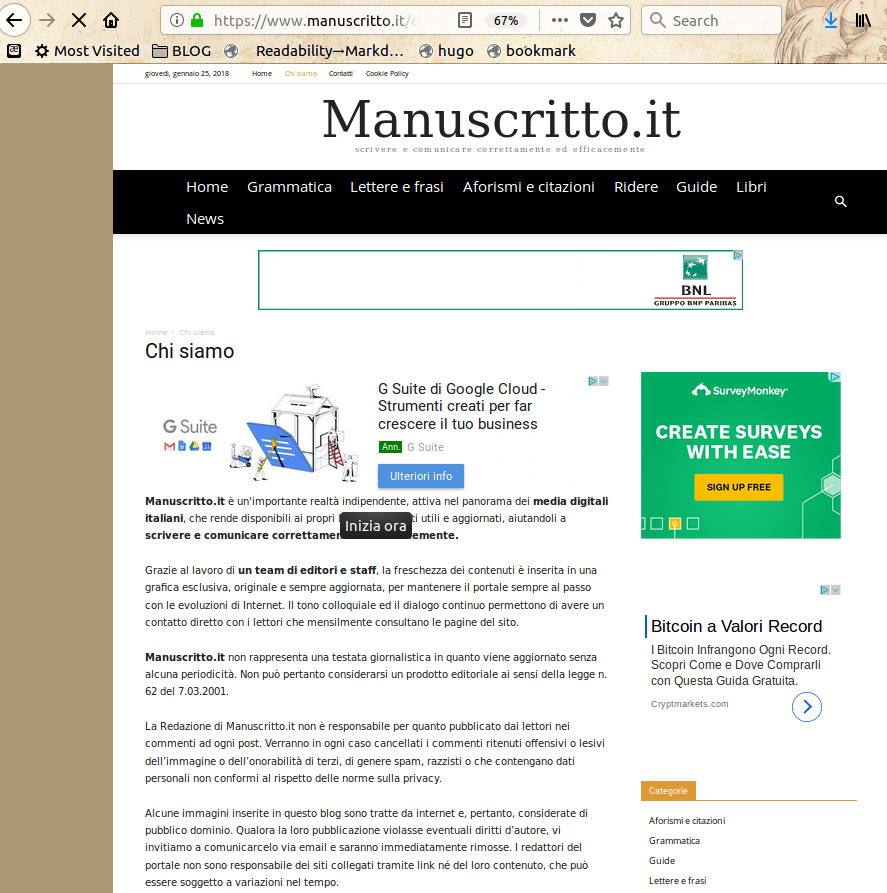
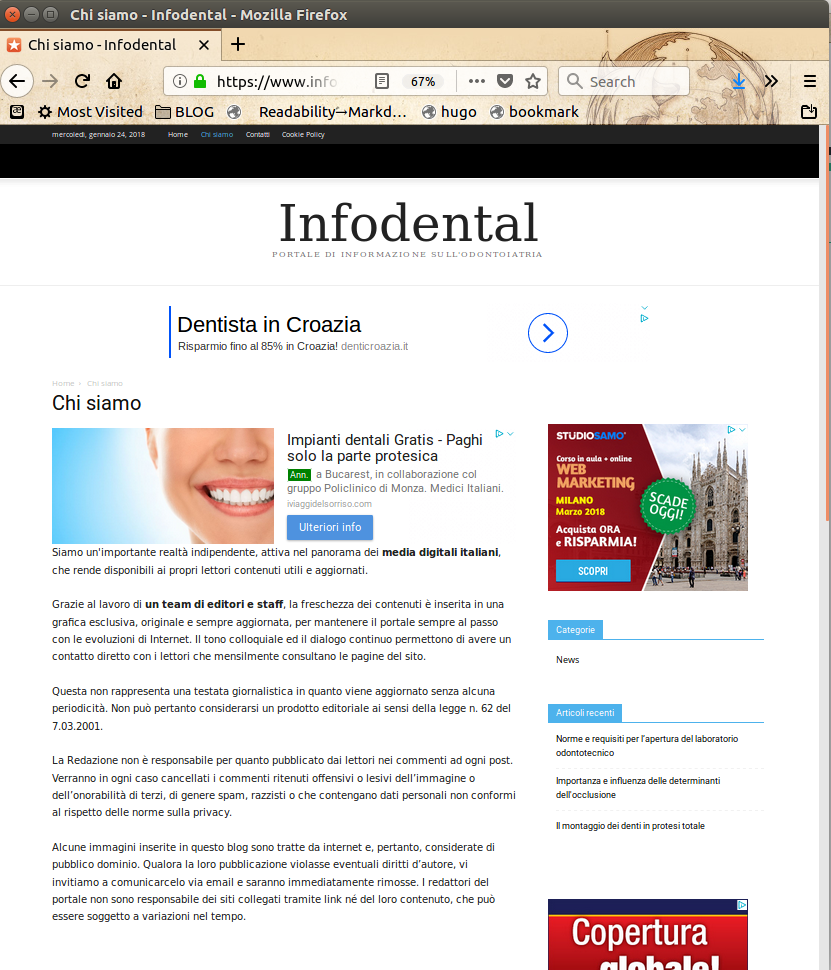
- www.manuscritto.it
- www.infodental.it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
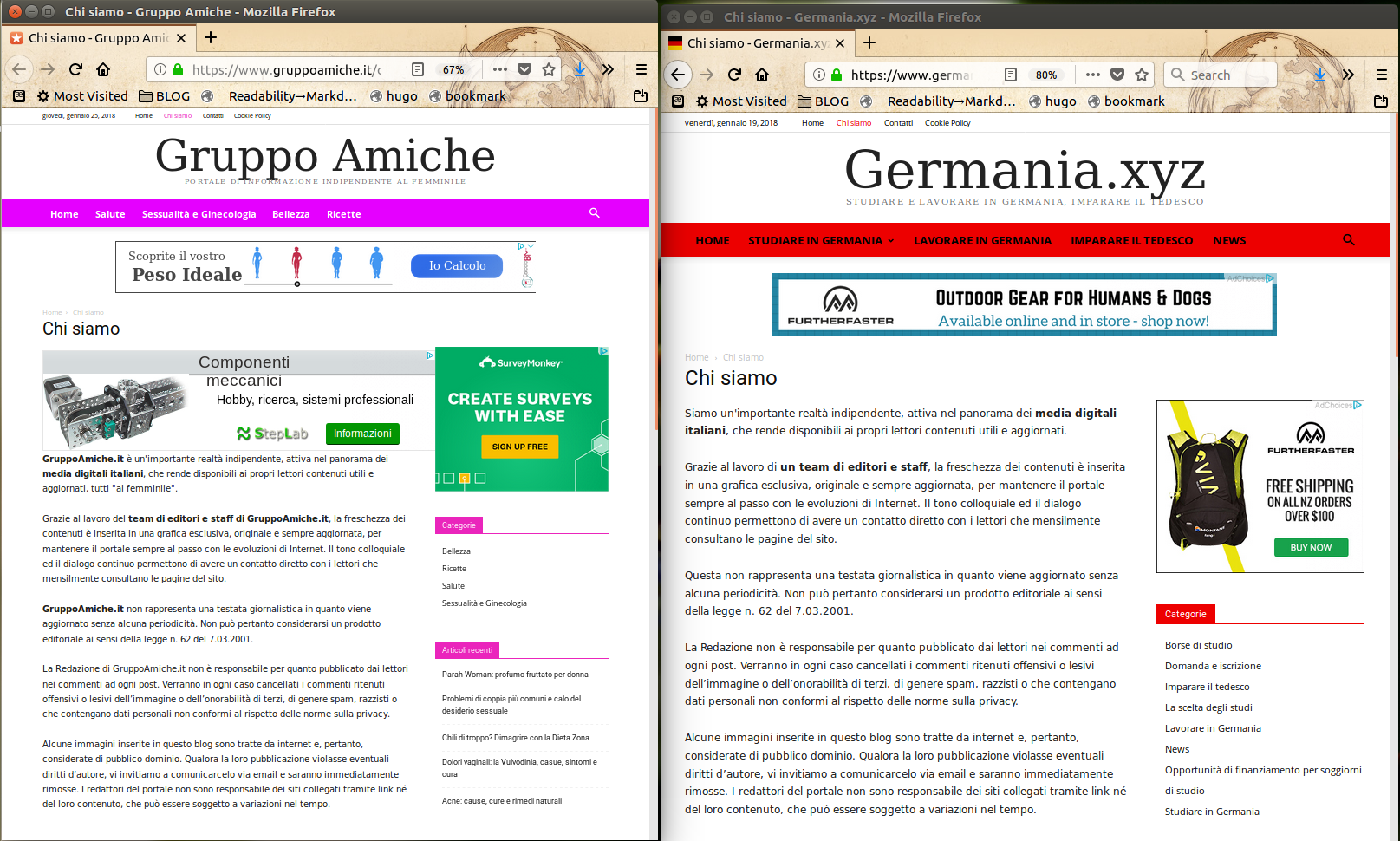
Tutti, non solo i primi due mostrati nella prima schermata, sono fatti con lo stampino (cliccare per credere sui link nella lista). Le loro pagine “Chi siamo” dicono tutte:
"Siamo un'importante realtà indipendente, attiva nel panorama dei media digitali italiani, che rende disponibili ai propri lettori contenuti utili e aggiornati."“Grazie al lavoro di un team di editori e staff, la freschezza dei contenuti è inserita in una grafica esclusiva, originale e sempre aggiornata… Alcune immagini inserite in questo blog sono tratte da internet e, pertanto, considerate di pubblico dominio."
ora, a parte il fatto che tanto esclusive e originali quelle grafiche non sono, quelle pagine suscitano domande come:
- perché una realtà davvero “indipendente” dovrebbe presentarsi copiando testi da chi si occupa di tutt’altro?
- se la “realtà indipendente” dietro tutti quei siti sugli argomenti più disparati è un’unico gruppo, perché non si dichiara per nome, visto che non ci sarebbe niente di male?
- come fa ogni “realtà importante” a spacciare ancora la COLOSSALE BUFALA che quello che sta su Internet è “considerabile di pubblico dominio”? Quella è la bugia più grossa di Internet
Freschezza dei contenuti? Sicuri?
Tutte quelle pagine dicono che “Grazie al lavoro di un team di editori e staff, i contenuti sono aggiornati e “freschi”. Vediamo.
La pagina “Lavorare in Germania: FAQ e informazioni generali” del sito numero 1 è copiata di sana pianta dalla pagina “Lavori per studenti e informazioni generali” del “Servizio Tedesco per lo Scambio Accademico”, in tedesco “DAAD - Deutscher Akademischer Austauschdienst”, il cui sito è www.daad.it (ma provate a visitare www.daad-italia.it, e ditemi dove finite):
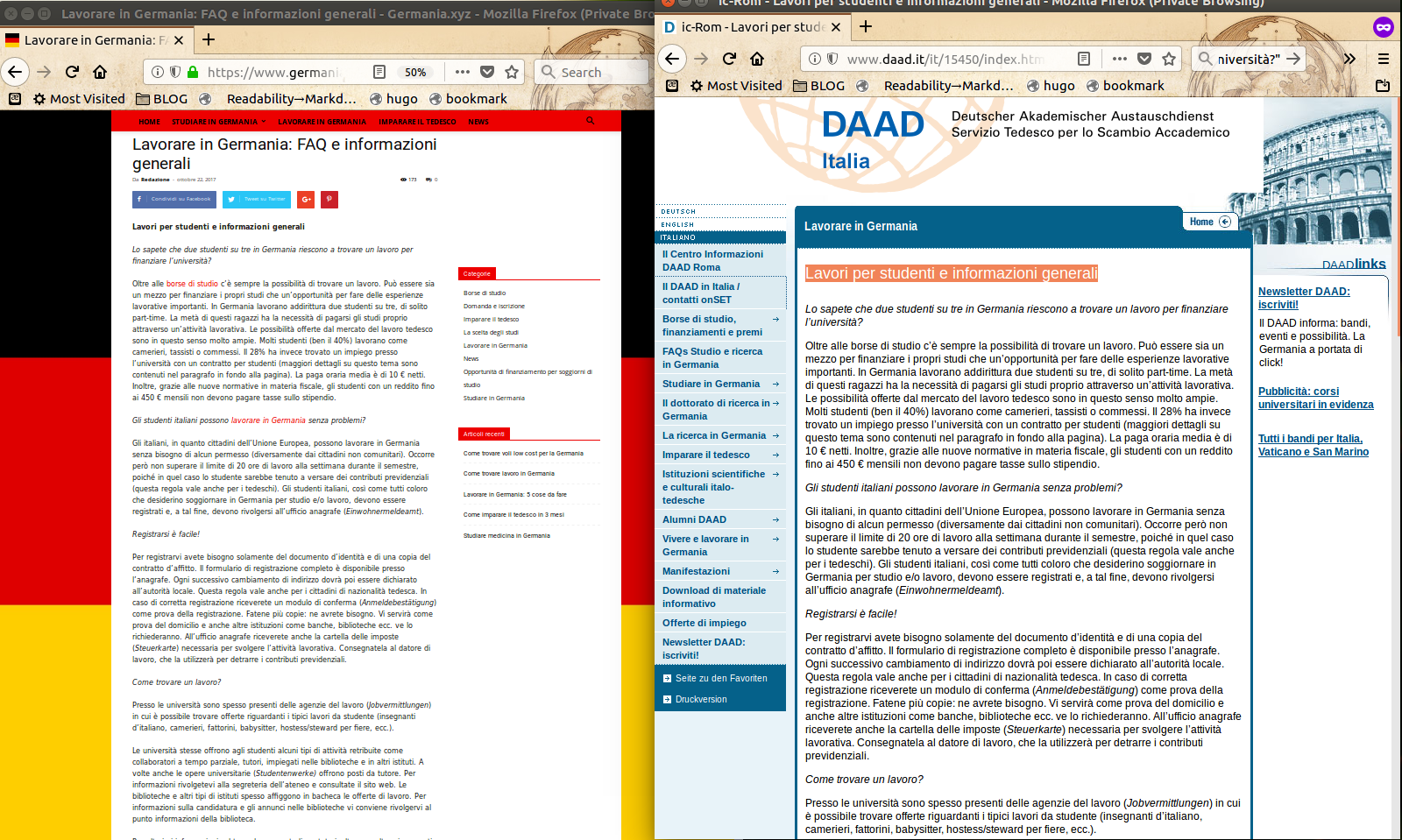
<u><em><strong>CAPTION:</strong>
<a href="/img/05-lavorare-in-germania-germania.xyz.vs.daad.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Il sito n. 4 ha una pagina copiata da questa di Pagamentidigitali.it, che in calce ha scritto ben chiaro “All Rights Reserved”:
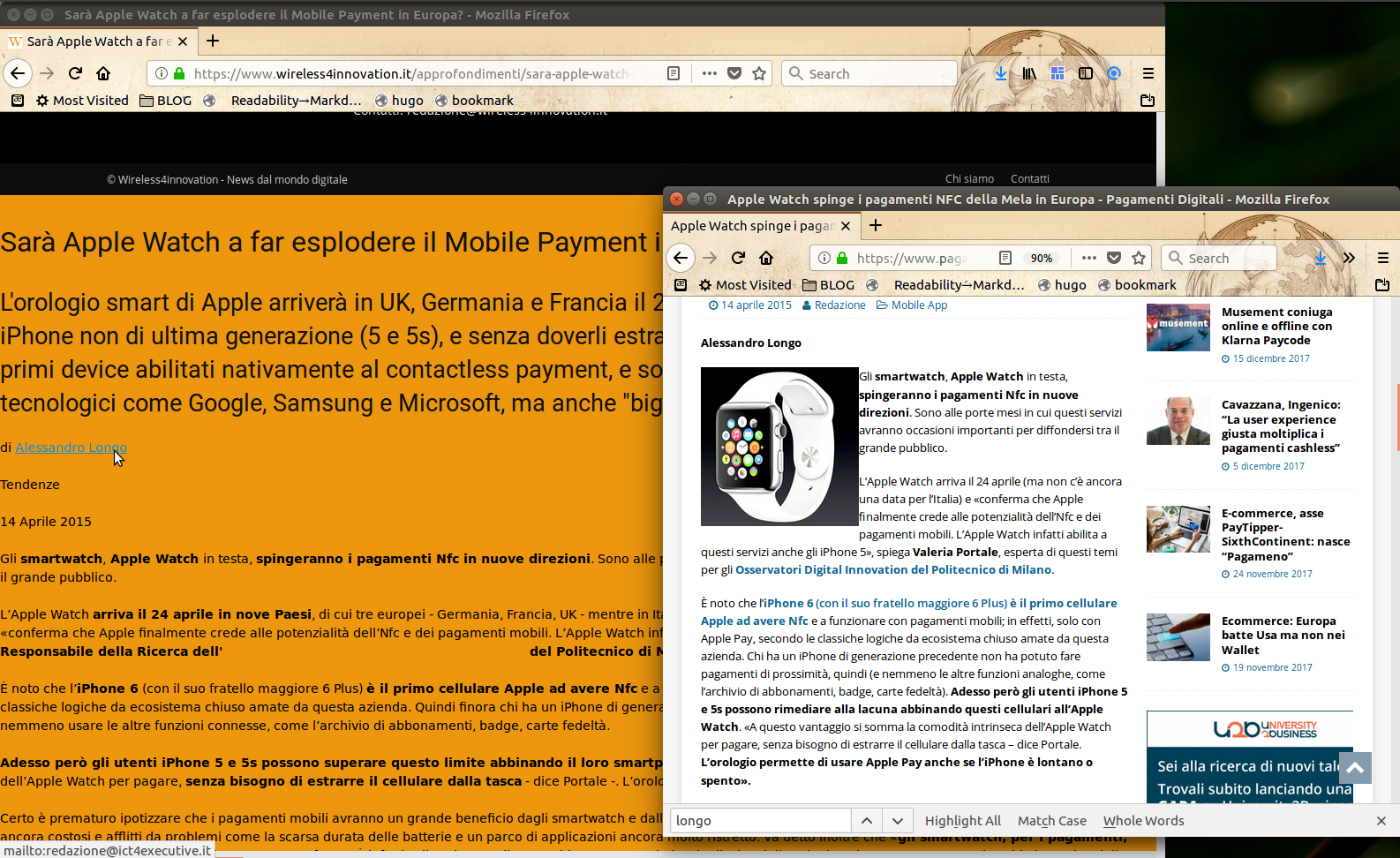
<u><em><strong>CAPTION:</strong>
<a href="/img/06-wireless4innovation-vs-pagamentidigitali.it.png" target="_blank">cliccare per versione più grande</a>
</em></u>
L’articolo sulla sezione aurea del sito n. 5 sembra copiato da qui e/o qui:
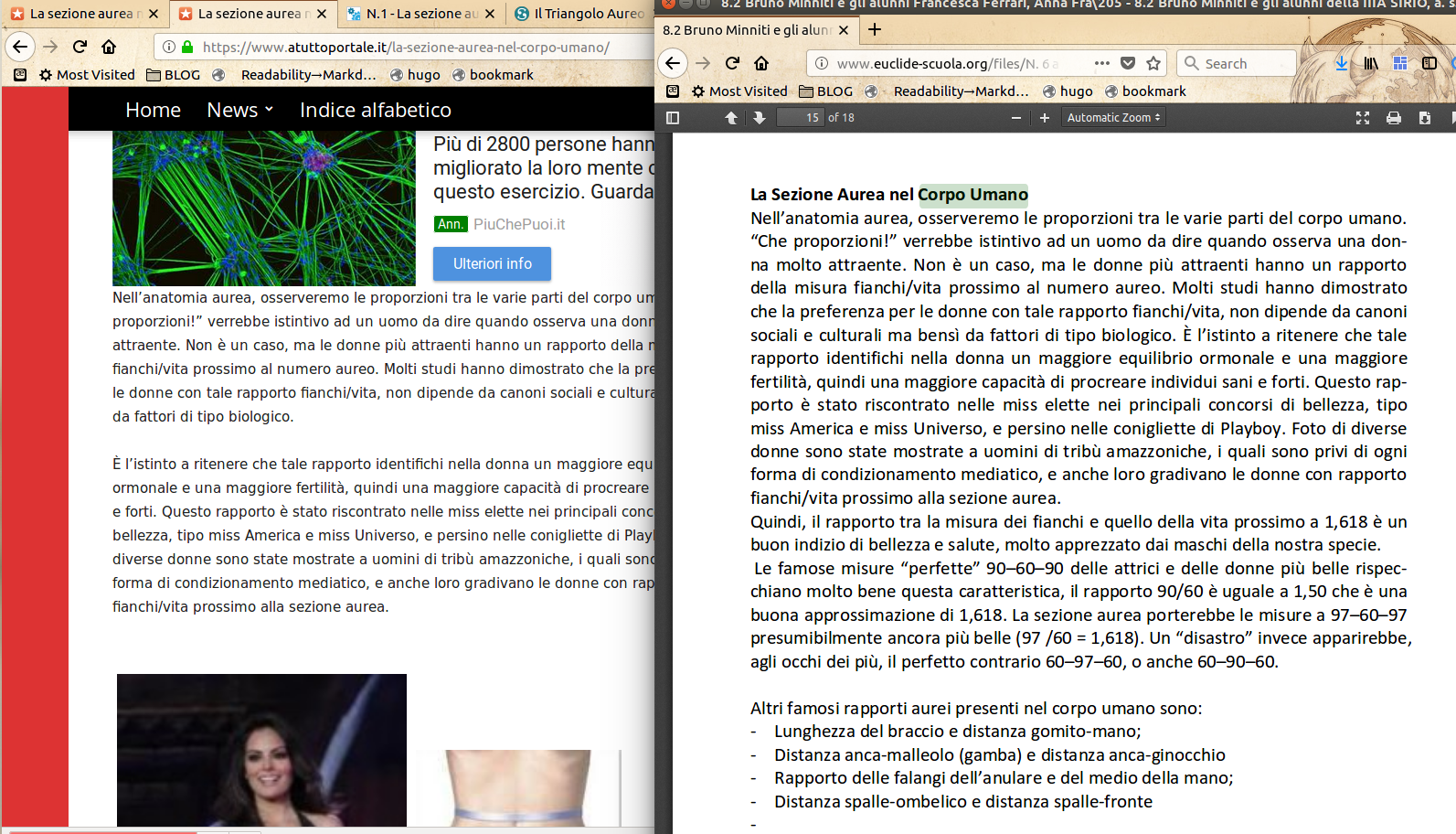
<u><em><strong>CAPTION:</strong>
<a href="/img/07-atuttoportalesezioneaurea.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Le “riflessioni sulle donne” del sito n. 6 sembrano un semplice copia e incolla da winnyweb e altre fonti:
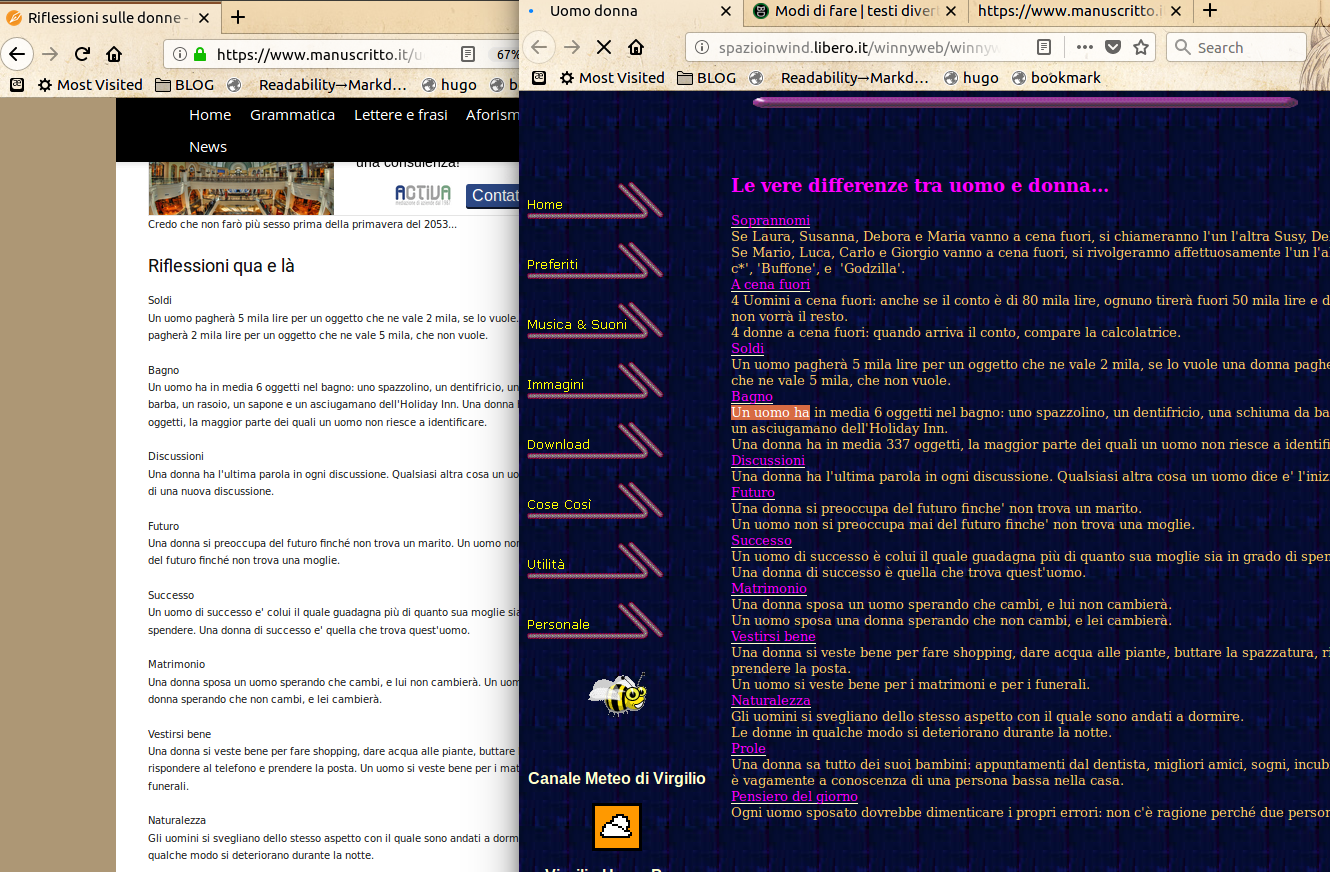
<u><em><strong>CAPTION:</strong>
<a href="/img/08-manuscritto.it-vs-winnyweb.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Le “Norme e requisiti per l’apertura del laboratorio odontotecnico” del sito n. 7 sono una copia parziale di questa pagina (e nessuna delle due è ufficiale, cioè in nessuno dei due siti hai la sicurezza di informazioni aggiornate e complete, o link a fonti ufficiali, su come avviare un’attività così delicata):
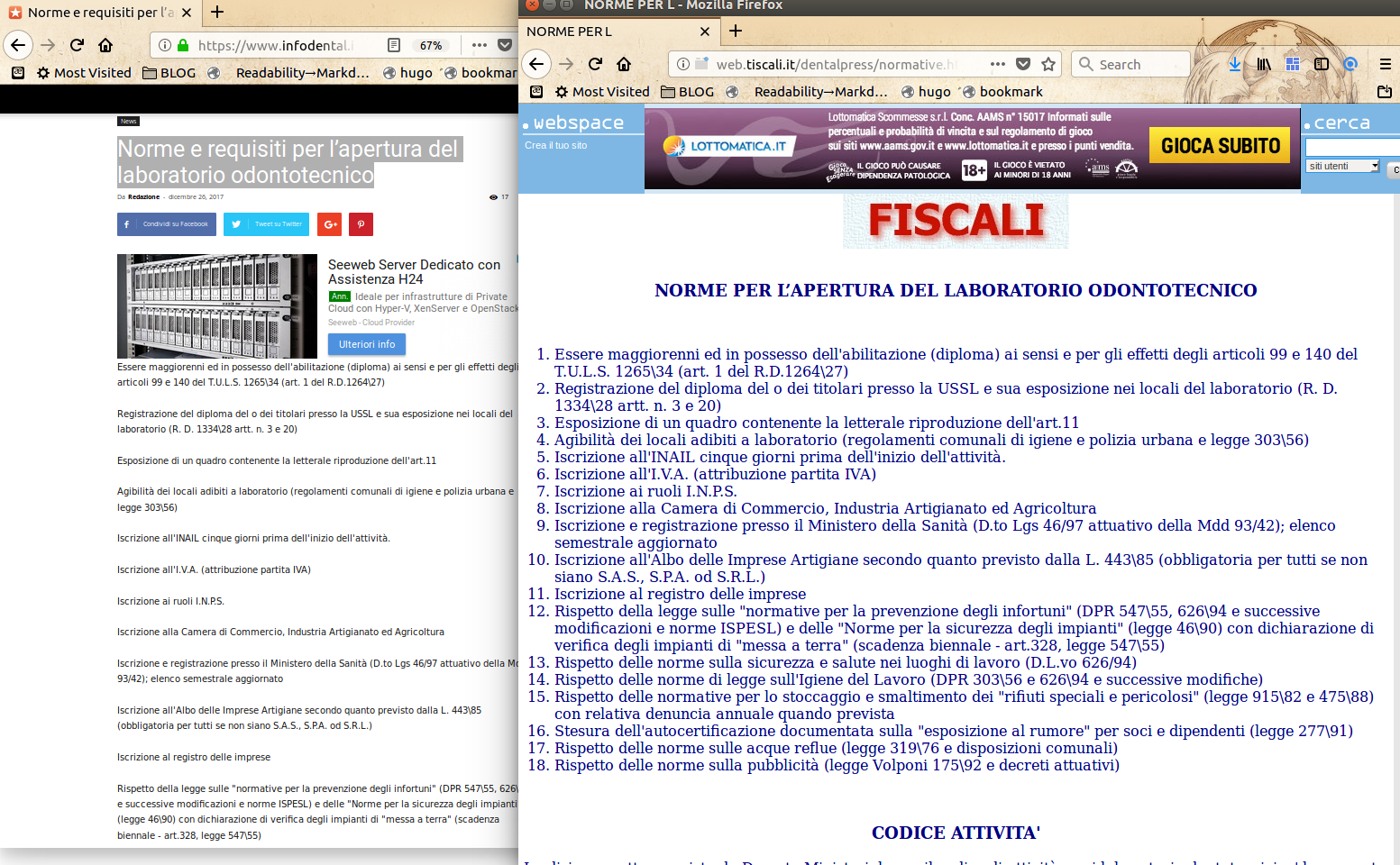
<u><em><strong>CAPTION:</strong>
<a href="/img/09-infodental.it-vs-dentalpress.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Ultimo ma non ultimo… la pagina del sito n. 2 in cui, a gennaio 2018, dei “Problemi di coppia più comuni e calo del desiderio sessuale” (testuale) “ci parla il “Prof. Marco Rossi, psichiatra e sessuologo noto al pubblico per la sua partecipazione al programma Loveline di MTV” contiene una foto presa (credo) da un articolo brasiliano di maggio 2017 (che ha scritto ben chiaro “Todos os direitos reservados “, mica “Pubblico Dominio”), e la prima parte del testo è quasi identica a una pagina di uno psicologo napoletano che non è prof. Rossi:
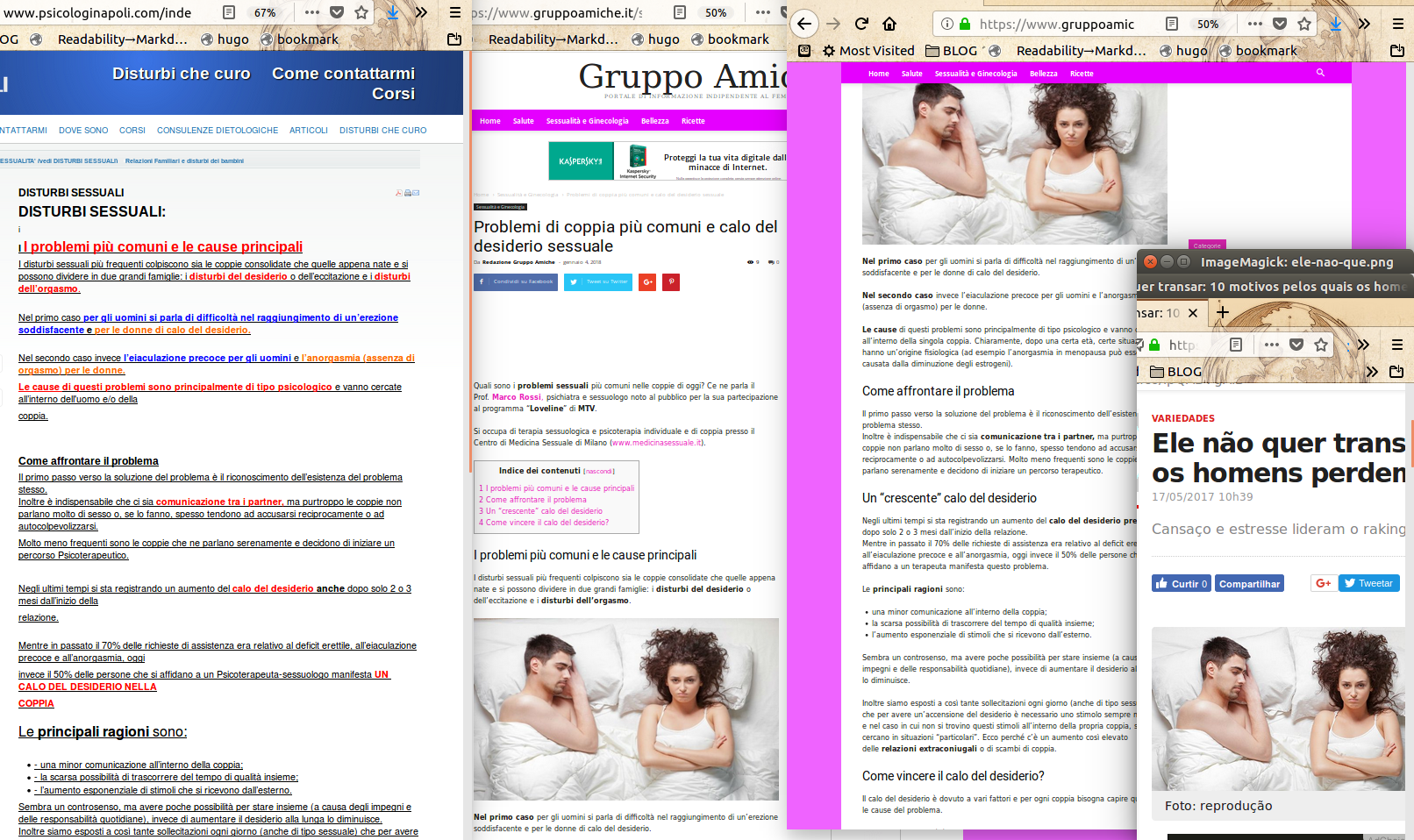
<u><em><strong>CAPTION:</strong>
<a href="/img/problemi-di-coppia.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Perché?
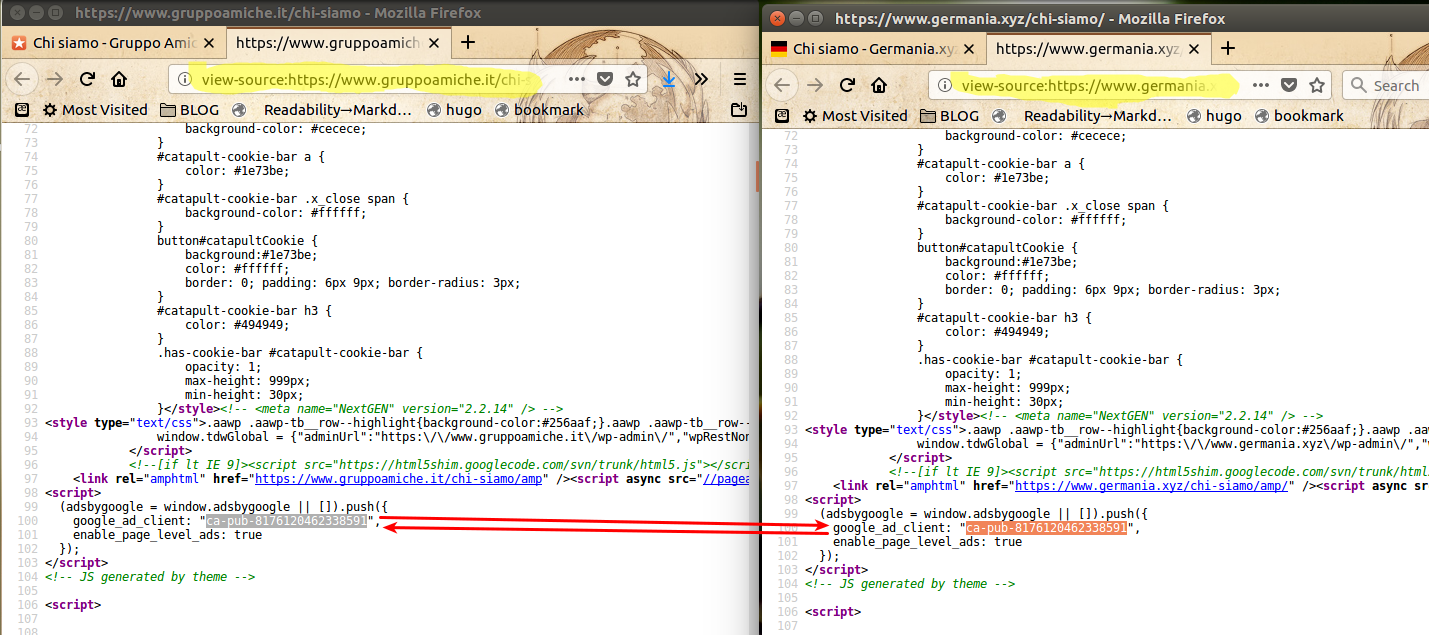
Un’occhiata al codice sorgente di quelle pagine “Chi siamo?” conferma la sensazione che siano tutte fatte da un unico gruppo, e ne mostra il motivo:
<u><em><strong>CAPTION:</strong>
<a href="/img/10-adsense-code-gruppoamiche.it-germania.xyz.highlighted.png" target="_blank">cliccare per versione più grande</a>
</em></u>
Provate anche voi, basta guardare il codice sorgente delle pagine: quei sette siti, non solo i primi due mostrati come esempio nella schermata qui sopra, contengono lo stesso codice Adsense (ca-pub-8176120462338591), il che vuol dire che i profitti da tutti i banner pubblicitari su tutti quei siti vanno nella stessa tasca.
Che dovremmo farne, dei siti con notizie clonate?
Nel fare o far fare soldi, anche tanti, con la pubblicità online, o nel marketing in generale non c’è ovviamente nulla di male. Nemmeno farlo in stile “Fattorie di contenuti” è necessariamente un male (se non sei uno di quei giornaloni spocchiosi che magari prende pure contributi pubblici per farlo).
Anche nel combinare, riformattare decentemente, in una parola RISCRIVERE davvero contenuti già esistenti, spendendoci il proprio tempo e fatica non c’è nulla di male (se si rispettano le licenza d’uso, ovviamente). Anzi spesso, in casi del genere, si fa un servizio di pubblica utilità, rendendo più chiare e fruibili cose già disponibili, ma scritte male.
Però usare su un sito, a scopo di lucro o no, anche contenuti copiati e basta, e senza nemmeno citare sempre le fonti… non mi sembra il massimo della professionalità. Nessuna “importante realtà indipendente” dovrebbe ricorrere a certi mezzucci. Anche se accade con un articolo su venti, e anche quando non si viola il diritto d’autore, come in qualcuno di quei casi. O no?
In pratica, se siete sicuri che un sito ha copiato qualcosa senza averne il diritto, o comunque violandone la licenza d’uso, non perdete tempo con gli avvocati. È molto più facile, economico e affidabile fare come faccio regolarmente io.
Il problema, casomai, è CHI contattare per risparmiare tempo e fatica. Soprattutto in casi come questi, quando chi effettivamente ha fatto le singole copiature, magari all’insaputa del titolare, potrebbero essere contrattisti indipendenti. Persone che magari nemmeno si conoscono fra loro e ignorano l’esistenza degli altri siti del gruppo. Si fa prima a cercare di capire chi è il titolare comune di tutti i siti (proprio perché, vedi sopra, molto probabilmente è un solo gruppo), e contattare direttamente lui. Come? Semplice. Si va su siti come Domaintools o Whois.net, si inserisce il nome del sito, si vede (se non è schermato…) chi risulta come contatto amministrativo e/o tecnico, e si cerca di rintracciarlo online.
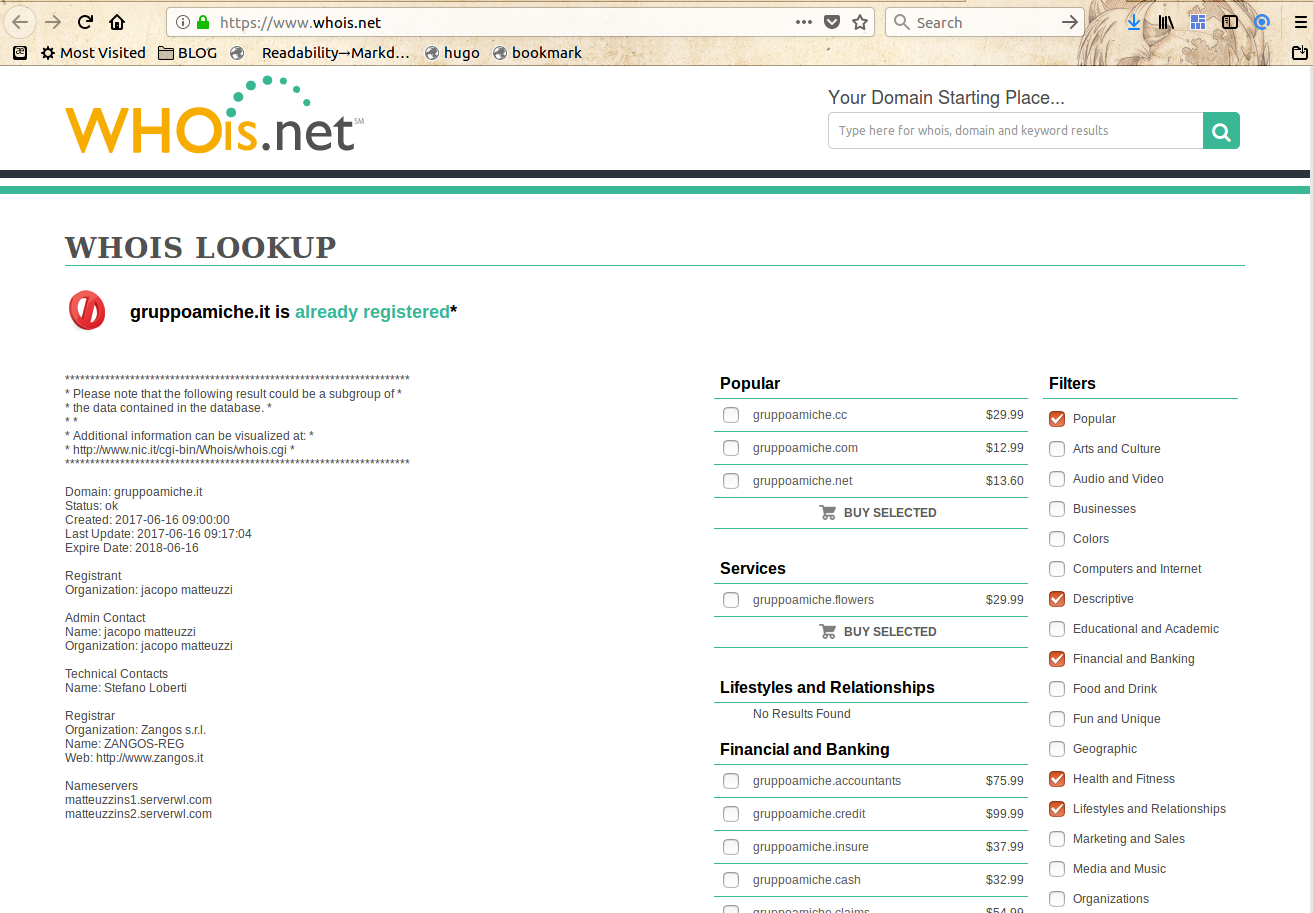
A titolo di esempio, nel nostro caso, i contatti del dominio sulla Germania sono nascosti, ma quelli del dominio GruppoAmiche risulterebbero essere, al 26 gennaio 2018:
<u><em><strong>CAPTION:</strong>
<a href="/img/01-registrant-gruppoamiche.it.png" target="_blank">cliccare per versione più grande</a>
</em></u>
tali Jacopo Matteuzzi (anche per i siti n.6) e n.7) e Stefano Loberti. I primi risultati che Google fornisce per quei nomi sono un Co-CEO di una agenzia specializzata in Web Marketing e un imprenditore specializzato nella pubblicità online. Molto improbabile che si tratti davvero di loro, per i motivi che ho già esposto. Ma ovviamente sono a disposizione per pubblicare smentite o chiarificazioni loro, o degli effettivi responsabili di quei siti, chiunque siano!
{kind=link}
{kind=link}
IMPORTANTE AGGIORNAMENTO, 17 LUGLIO 2018:
Il signor Stefano Loberti mi ha appena fatto giustamente notare che lui risulta (come potete vedere cercando di nuovo quei domini su WHOIS) solo come contatto TECNICO (ovvero NON titolare di un sito, o comunque responsabile in alcun modo del suo contenuto!) “in quanto, come da regolamento registro Italiano nomi a dominio, se non richiesto espressamente dal registrante il tecnico deve essere dell’azienda accreditata (quindi la zangos srl in questo caso io).”
Mi scuso per non aver evidenziato questa fondamentale distinzione nella prima versione del post.
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!