Alfabetizzazione mediatica o PDF immagine. Scegliete
È appena uscita la bozza di un disegno di legge bipartisan per “per prevenire la manipolazione dell’informazione online, garantire la trasparenza sul web e incentivare l’alfabetizzazione mediatica”
A giudicare dalle prime reazioni avremo modo di riparlarne parecchio, con più calma e con gusto (magari dolceamaro). Per cominciare, visto che l’obiettivo è anche “incentivare l’alfabetizzazione mediatica”, ecco un modesto contributo su quel fronte:
PDF immagine? Nel 2017? ANCORA???
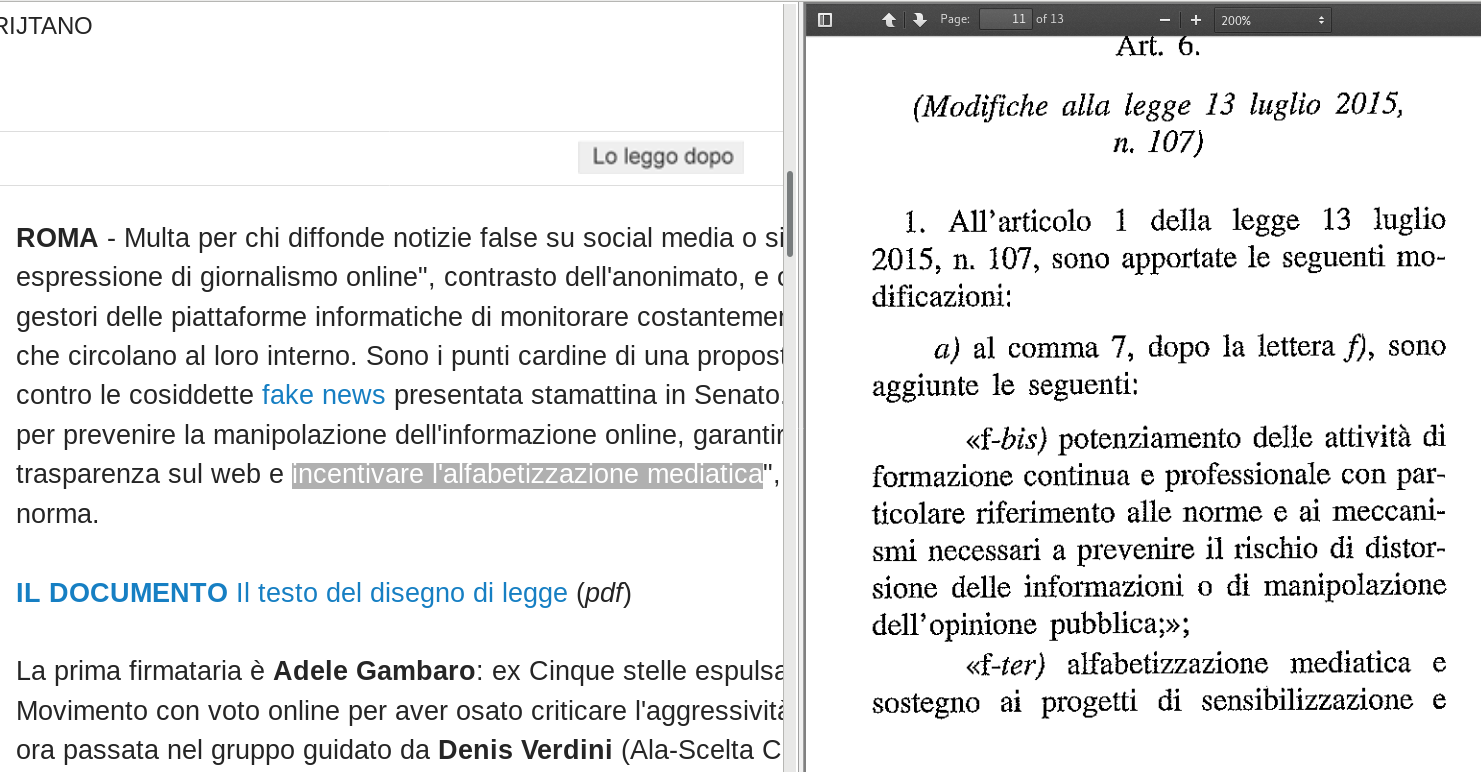
La bozza del disegno di legge in questione è disponibile online come PDF immagine e questo non va bene.
Spiegazione del termine: i file “PDF immagine” sono quei file PDF che NON sono generati a partire da file di testo, ma “salvando come file PDF” una scansione, cioè sostanzialmente una fotografia, di un foglio stampato:
- I file PDF veri conservano il testo come tale, cioè selezionabile, copiabile, analizzabile automaticamente automaticamente… Quelli “immagine” NO, perché sono, appunto, delle fotografie di un testo.
- I PDF veri hanno parecchi limiti, ma almeno rimangono utilizzabili per citare e riusare un testo, ingrandirlo senza sgranare, stamparselo come si deve, analizzarlo automaticamente… Quelli immagine, NO, per lo stesso motivo già detto
- ah, e i PDF immagine non sono nemmeno accessibili dai cittadini ipovedenti, cosa che NON va bene:
“Gli Uffici, inoltre, devono sempre tenere presente la normativa in materia di accessibilità dei documenti (contenuta nella L. n. 4/2004) non pubblicando PDF immagine (come le scansioni di documento cartaceo, che rendono la pubblicazione inefficace” Fonte: LINEAMENTI DI INFORMATICA GIURIDICA
In sostanza, i PDF immagine, soprattutto di testi che esistono sicuramente anche in formati digitali, sono file metà inutili e metà ridicoli e sintomo di disinteresse o scarsa competenza, in moltissimi casi pratici. A partire da quelli in cui si vuole “incentivare l’alfabetizzazione mediatica”.
Per essere presi seriamente, oltre a dire cose sensate, giuridicamente corrette e concretamente realizzabili (cosa che, personalmente, per ora non posso escludere, e comunque se ne riparlerà sicuramente) una legge per “incentivare l’alfabetizzazione mediatica” e i suoi firmatari dovrebbero anche, immediatamente, già dalle bozze, essere presentati in formati completamente utilizzabili (*)
Anche perché dell’inadeguatezza dei PDF immagine se ne parla da un pezzo. Ecco qualche link in Italiano:
- slide 28 di “Open Data: come fare”
- Terza stazione di questa “via crucis”
- (in Inglese) “Pulling data out of PDF documents can be an arduous task”
(*) se poi leggi e proposte di legge cominciassero a gestirle come si deve, cioè così, sarebbe la cosa migliore, altro che PDF immagine o no
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!