Google semble bien "oublier" le Web ancien
Selon Tim Bray, pionnier du XML et blogueur de la première heure, Google semble souffrir de trous de mémoire délibérés. Voici un témoignage de plus qui pourrait montrer que c’est bien le cas…
(Translation from French of this other post, kindly provided by Florian Gambardella)
Selon Tim Bray, pionnier du XML et blogueur de la première heure, Google semble souffrir de trous de mémoire délibérés. Voici un témoignage de plus qui pourrait montrer que c’est bien le cas. Je cite Bray: “Je pense que Google a cessé d’indexer les plus vieilles régions du web. Et je pense que je peux le prouver. Les concurrents de Google sont meilleurs.”
L’exemple de Bray: une critique datant de 2006
En 2006, Bray publie la critique d’un album de Lou Reed sur son blog personnel. Quand, il y a quelques jours [en janvier 2018], il souhaite en partager l’URL, il se rend compte qu’il n’arrive pas à le retrouver via Google. Et ce “même en consultant d’abord l’article, en faisant bien attention d’entrer les termes exacts dans la barre de recherche, et en utilisant le préfixe ‘site:’”.
Mon propre exemple, datant lui aussi de 2006
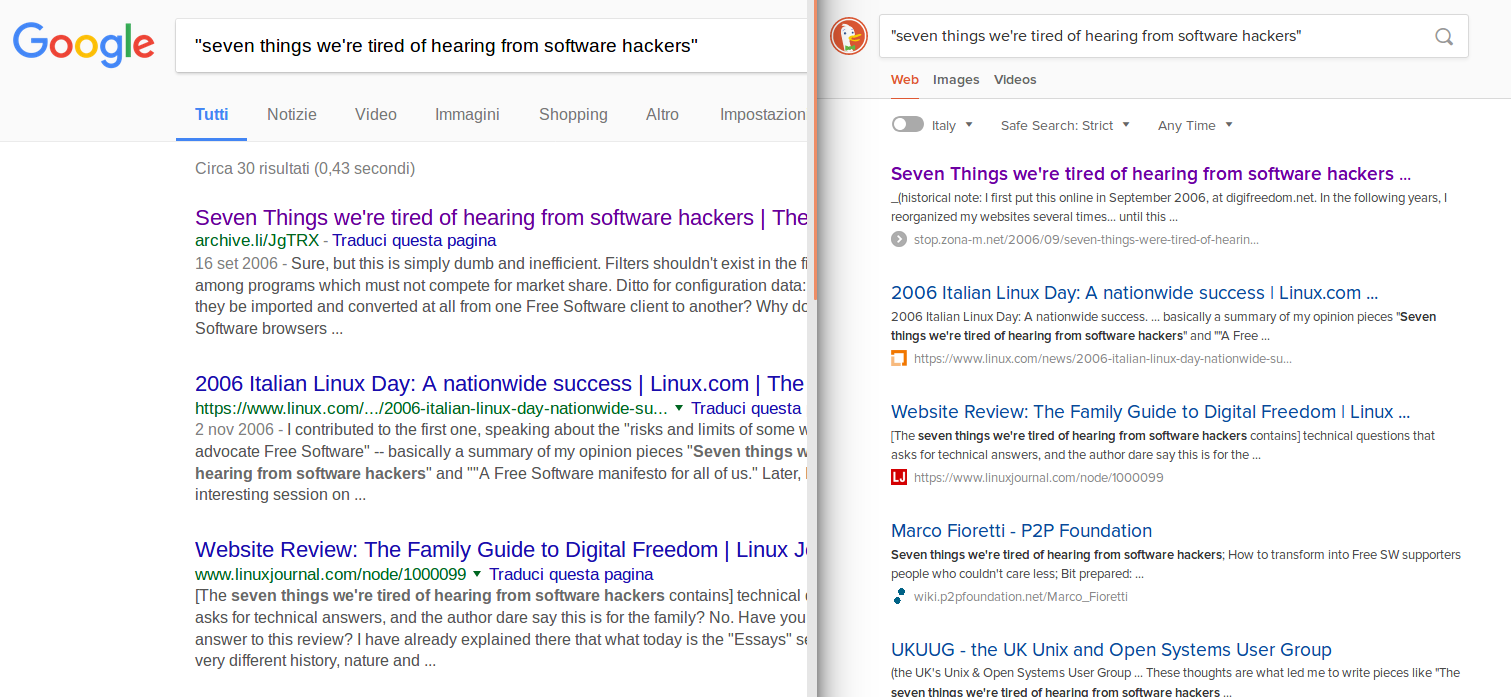
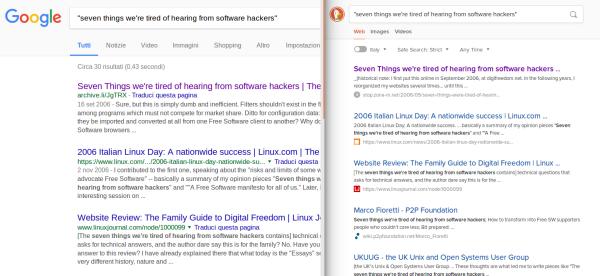
En 2006, j’ai publié sur l’un de mes domaines, digifreedom.net, ce billet d’opinion: “Seven Things we’re tired of hearing from software hackers”. Quelques années plus tard, pour des raisons sur lesquelles je ne m’étendrais pas ici, j’ai gelé le projet. Conséquence collatérale, l’article sur les “Seven Things”, avec quelques autres publications, n’étaient plus accessibles. En décembre 2013, j’ai pu remettre en ligne l’article, à cette adresse sur cet autre site. Et lorsque samedi dernier [le 12 janvier 2018], j’ai voulu envoyer ce lien à un ami, j’ai vécu la même chose que Bray: Google ne faisait remonter que des mentions de l’article, voire des copies entières, mais qui étaient archivées ailleurs. J’ai demandé à Google de réindexer l’ensemble du site - sans effet. Et puis, hier après-midi [le 16 janvier], je suis tombé sur l’histoire de Bray sur BoingBoing. J’ai aussitôt reproduit l’expérience sur DuckDuckGo, avec le même résultat: alors que Google ignore ma version de mon propre article, DuckDuckGo le référence correctement, en première position (cliquez ici pour une capture d’écran en haute-résolution):
{kind=link}
Deux situations différentes, un même résultat?
Contrairement à celle de Bray, mon article a disparu du Web pendant un moment, puis a été remis en ligne avec sa date de publication d’origine - mais quelques années plus tard, et sur un domaine différent. Il s’agit d’une différence importante. Une différence qui pourrait nous faire considérer que, dans mon cas, je suis en partie responsable de l’échec de référencement de Google. Pourtant, en pratique, le résultat est le même:
DuckDuckGo référence en première position la réponse la plus pertinente - et à vrai dire la seule réponse à laquelle s’attend quelqu’un intéressé par ce post aujourd’hui: le lien actuel, vers la version originale, sur le site (actuel) de son auteur. DuckDuckGo réussit. Google échoue - aujourd’hui, pas à l’époque de la rédaction bien sûr.
Bray en conclut que Google oublie délibérément les pages anciennes, parce qu’“indexer l’ensemble du Web est absolument hors-de-prix, et l’est chaque jour un peu plus.” Ce que veut Google, ajoute-t-il, c’est “vous apporter les bonnes réponses aux questions qui vous intéressent à l’heure actuelle.” Sa conclusion? Si le Web doit devenir “une archive durable, sur le long terme, du patrimoine intellectuel de l’humanité… il doit être indexé, comme on le ferait dans une bibliothèque. Google n’est apparemment pas de cet avis.”
Je suis d’accord avec lui. C’est d’ailleurs pourquoi je trouve que le titre choisi par BoingBoing quand ils ont relayé cette affaire induit en erreur: “Google oublie le web des origines”, ont-ils titré. Mais les deux publications dont on vient de parler ne font pas partie du “web des origines” - elles ne sont d’ailleurs pas si “vieilles” que ça. A moins que nous n’ayons raté quelque chose, il semble plus correct de dire que Google oublie ce qui est vieux de plus de 10 ans. Si c’est bien le cas, chaque année, Google se souviendra et indexera une portion du web de plus en plus petite. Google fait ce choix tout simplement parce qu’il leur est impossible de faire mieux, en raison de contraintes économiques et/ou techniques. Et ses concurrents vont être confrontés tôt ou tard au même problème. Cela ne fait par ailleurs que rendre de plus en plus grand le problème de savoir de quoi se souvenir, et quoi oublier. Et surtout de savoir qui devrait choisir de retenir et d’oublier, et comment.
Tant que vous êtes là… Si vous avez aimé cet article, pourquoi ne pas me soutenir via PayPal, LiberaPay, ou via ces autres moyens de soutenir mon travail? Et voici POURQUOI je pense que vous pourriez vouloir le faire.
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!