Thoughts and Tips from the 2013 Open Data Week
I participated to the 2013 Open Data Week in Marseille to lead a workshop on an idea I had a couple years ago, one that seems to be more and more ready to seriously take off every month:

Open Data in and from schools. While in Marseille, I first heard about Open Data developments in Sayada and the rest of Tunisia. Then I also heard that…
OpenFoodFacts is great and needs you
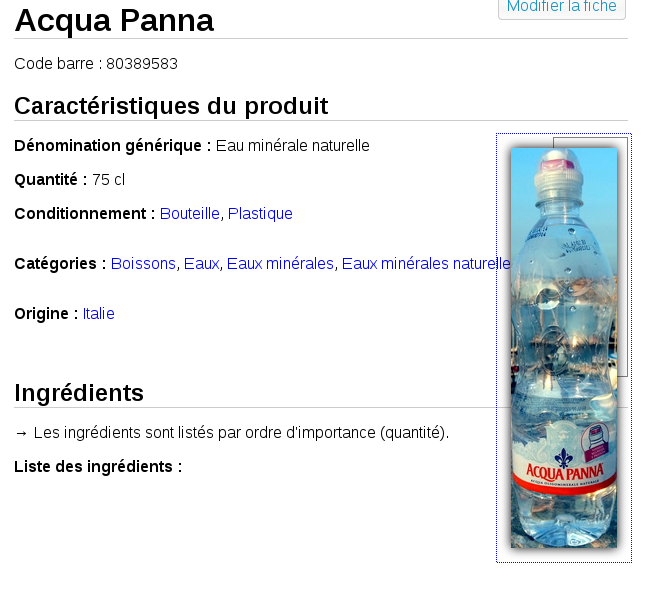
The free, open and collaborative database of food products OpenFoodFacts is great. It is both in and by itself, and because it shows (as I wrote a couple years ago]) that we need better definitions: Open Data often is, or should be, in Stephane’s words, “not public data but data of public interest”. With respect to OpenFoodFacts, the first things it needs (and if you ask me, schools really looks like good partners for it, see above) is local presence and advocates in many parts of Europe. Everybody can help, everywhere: when Stephane saw in my backpack a bottle of mineral water bought in the Fiumicino Airport he immediately took a picture of its label “because we still have so little data from Italy”. Now, as you can see in the screenshot, even that mineral water is in the OpenFoodFacts database, thanks to a casual meeting.
Crowdsourcing is not magic
From Olivier Rovellotti (here are his slides): crowdsourcing is just very efficient (and this is where its actual value is) in distributing the dumber tasks, that would otherwise consume all the time of the very few specialists in any given field, to the large numbers of well meaning non-experts that couldn’t help in any other way. “All” you need to do to make crowdsourcing work is to “align complexity with number of crowdsourcers”, that is to partition the problem in most numerous but simplest task and so on.
During the June 27th workshop on crowdsourcing the same concept came back as “don’t waste time of very knowledgeable people with simple tasks”. We also discussed how to extend crowdsourcing to more domains and communities, starting from the assumption that successful crowdsourcing must:
- be simple to participate in
- be visibly useful (making very clear, in some cases, that it may be useful only to people not doing the actual job)
- give clear visibility of the project to which it will contribute, and of its intended outcomes
Simple, really open specifications are good (with a note for OOXML fans and Google Reader victims)
The General Transit Feed Specification (GTFS) was developed bottom-up to just get (interoperable) automatic trip planning with public transportations done. Nothing more, nothing less. And it’s just for these reasons that it works quite well and is widely adopted. Much more, in any case, than over-complicated specs mostly created to push somebody’s agenda. Thanks to Andrew Byrd for explaining it well! And speaking of trip planning, please do read the great slides of Pieter Colpaert on Open Transport.
Outside of Open Data, the success of GTFS seems to me good food for thought for everybody thinking that OOXML makes more sense than ODF. Or, in a different space, that the end of Google Reader isn’t just a wonderful occasion to give RSS the respect (and usage) it deserves and we need.
Final quotable quotes
- Steven Flower: “go for new markets: slow and small data”
- Stephan Martayan: “talking of open data shouldn’t be only with developers”
- Amandine Brugiere: “add coding, math algorithms, statistic courses in school curricula”
- Pieter Colpaert: “Governments must tell transportation companies to open up their data as part of their service!”
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!