The globalization of evil autocompletion
Beware of cliche' search engines!
You may already know that the autocomplete feature of Google, and other search engines, can be controversial, or worst. If it’s any consolation, it is equally bad everywhere.
Two preliminary papers (here and here) by Dr. Yidnekachew Redda Haile and other researchers, describe how problematic the Google Autocomplete predictions are in Indigenous East African Languages, namely Amharic, Swahili and Somali. In this screenshot, for example:

the Amharic autocomplete for keywords related to women are very sexualised and pornified against the Ethiopian culture and norms. In this one, instead:
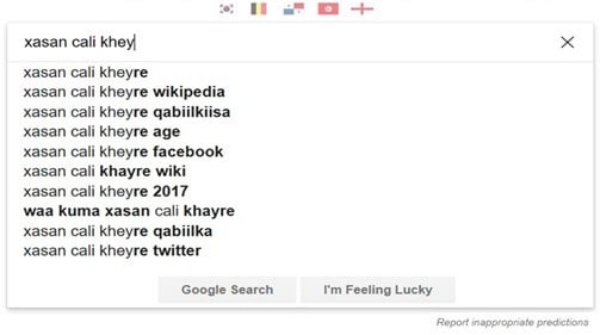
the autocomplete results for politicians related Somali Keywords include words, such as “clan”, that are highly divisive in that context.
It’s people, not (just) Google
In my own opinion, the initial culprits of things like these are people, not Google for sure. If what enough people only search online the age, or bra size, or ethnicity of other individuals, instead of what those same individuals actually do or say… then the search engine will believe that all its users have the same priorities, and react accordingly.
All this does not change the fact that it is very important to discover, and document, all these suggestions and reinforcements of stereotypes. The opposite is true.
Dr. Haile and his colleagues rightly ask “if the first Search prediction for the Somali word for “girl” is “naked” (which it was in our test) then is this acceptable? Who gets to decide? Or what does this “prediction” actually tell us?"
My answer to the last question is that screenshots like those, and the underlying research, should be shown, and explained, in any “internet literacy” class.
An important reason for doing so is that solving what we may call the “root problem”, that is preventing the autocompletion (or “prediction”, as Google itself calls it) feature would be practically impossible to do, and with side effects worst than the one it should cure.
The question is, can the same human beings who create and (often even unconsciously) perpetuate unfair and divisive stereotypes really expect to give software definitive instructions of how to not repeat them? Or trust any software from learning itself, starting from unavoidably biased data? Or have one software do it equally well, for thousands of wildly different cultures?
The other issue is that, no matter how one tweaked a search engine, the result would be some form of censorship. That is why, I believe, the authors of those paper raise questions about “the desirability of (and responsibility for) policing “inappropriate” search predictions”.
Which autocompletions would you block, if you were Google?
Who writes this, why, and how to help
I am Marco Fioretti, tech writer and aspiring polymath doing human-digital research and popularization.
I do it because YOUR civil rights and the quality of YOUR life depend every year more on how software is used AROUND you.
To this end, I have already shared more than a million words on this blog, without any paywall or user tracking, and am sharing the next million through a newsletter, also without any paywall.
The more direct support I get, the more I can continue to inform for free parents, teachers, decision makers, and everybody else who should know more stuff like this. You can support me with paid subscriptions to my newsletter, donations via PayPal (mfioretti@nexaima.net) or LiberaPay, or in any of the other ways listed here.THANKS for your support!